-
데이터과학을 위한 통계 리뷰 - 16일차 (가설검정,이분산성,영향값,회귀 진단,이분산성,영향값,다수의 수준을 갖는 요인변수들)Machine Learning/데이터과학을 위한 통계 2021. 3. 16. 13:15반응형
4.5.4 상호작용과 주효과
주 효과: 다른 요인(집단구분 변수)과 상관없이, 예측변수의 수준(집단)에 따라 효과가 유의미하게 달라질 때
상호작용 효과: 한 요인의 수준에 따른 효과의 차이가
또 다른 요인의 수준에 따라 달라질 때
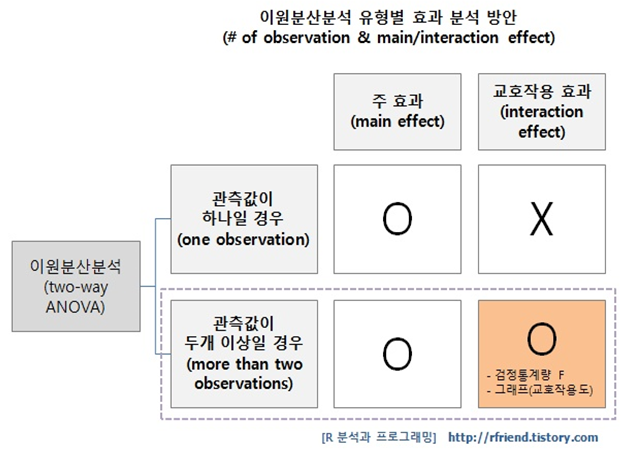
Two-way ANOVA
이원분산분석은 주효과와 상호작용효과 분석 가능

출처:
https://heung-bae-lee.github.io/2020/01/15/machine_learning_04/
Regression(03) - 회귀진단
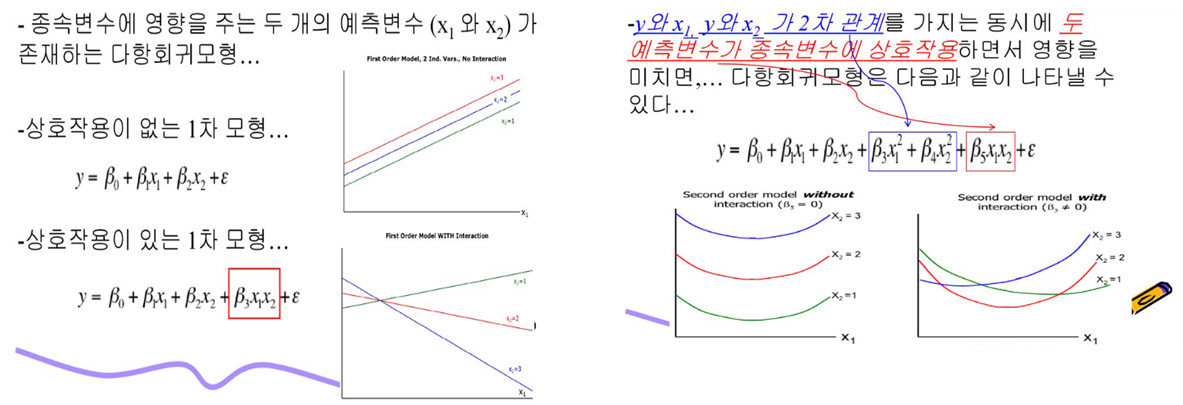
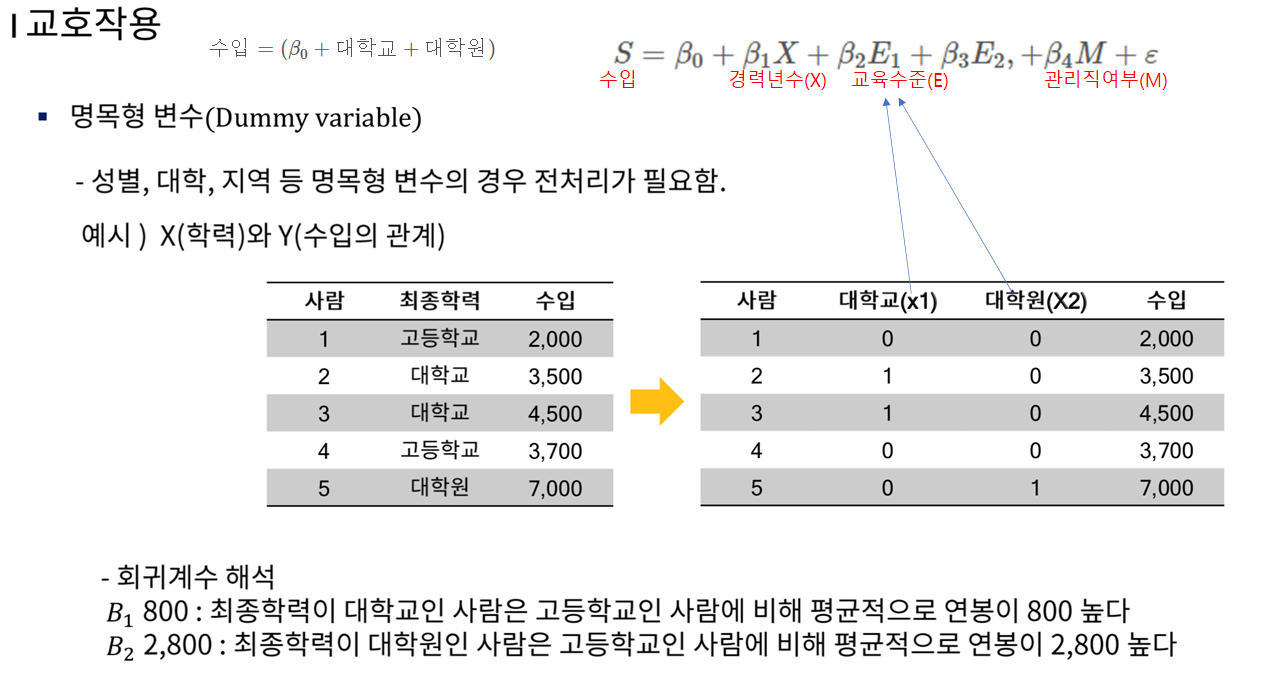
교호작용 성별, 결혼여부, 혹은 소속 정치단체 등과 같은 질적(qualitative) 또는 범주형(categorical)요인들이 회귀분석에서 종속(반응)변수의 변화를 설명하는 데 매우 유용한 독립(설명) 변수 역할을
heung-bae-lee.github.io
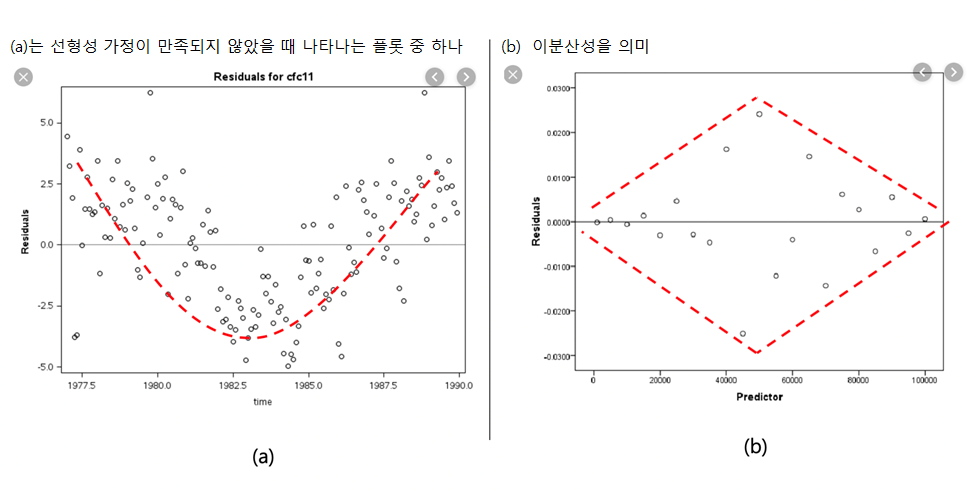
(Standardized) Residual vs Predictor(독립변수) 산점도
표준적인 가정 하에서 표준화잔차는 각 독립(설명)변수들과 상관되어 있지 않다.
이 가정이 만족된다면 이 플롯은 랜덤하게 흩어진 점들이 나타나야 한다.
독립변수(예측변수) 간의 관계를 적절히 표현하지 못할 때 Interaction 항이 필요함

왼쪽의 경력년수와 표준화 잔차의 플롯을 보게 되면, 셋 또는 그 이상의 서로 다른 수준의 표준화 잔차가 있음을 볼 수 있다.
이는 교육수준과 관리직 여부의 영향을 나타내는 즉 현재 보여주는 변수를 제외한 나머지 변수들이 적절하지 않음으로써 생긴 현상일 수 도 있다.
오른쪽의 교육수준 × 관리의 가능한 6가지 범주조합의 표준화잔차 플롯을 살펴보면 6가지 범주조합에 따라 체계적인 군집을 이루고 있음을 볼 수 있다.
허나 각 조합내에서 잔차들은 거의 전부 양이거나 음의 값을 취하고 있다.
이러한 현상은 위의 모형식이 급료(S), 경력년수(X), 교육수준(E), 관리직의 여부(M)의 관계를 적절히 표현하지 못한다는 것을 의미한다.

교육과 관리직의 여부의 교호작용항을 추가해 주어서 다시 표준화잔차 vs 경력년수의 플롯을 살펴보면 이와 같다.
단 하나의 관측개체에 의해 회귀계수의 추정값이 지나치게 많은 영향을 받고 있으므로, 해당 특이값을 제외하고 시행한 회귀분석의 결과
전체적으로 회귀계수의 추정값에는 별 변동이 없었으며, 잔차들의 표준편차가 오히려 줄어들었고, 결정계수가 늘어났다고 가정하자.
그렇다면, 해당 특이값을 제외한 모형식으로 적합을 시켜주는 것이 옳은 것이다.

그러나, 해당 모형의 질적변수의 회귀계수에 대한 해석을 함에 있어서는 각 범주별로 회귀계수를 더해주면 된다.
물론 상수항을 포함하여 계산하여야 할 것이다.
위의 방법과 다르게 처음부터 6개의 범주를 만들어 가변수를 취해 동일한 모형을 적합하는 방법도 있는데,
위의 방법이 가지는 장점은 3가지 예측변수 (교육수준, 관리직의 여부, 교육수준-관리직의여부)가 가지는 효과를 명백하게 구분할 수 있다는 점이다.

출처:
https://datascienceschool.net/view-notebook/7dda1bc9ad1c435fb309ea88f672eff9/


4.6 가설 검정: 회귀 진단
* 가정 검정 : 모델을 뒷받침하는 가정들이 얼마나 잘 들어맞는지 검정하는 것
직접적으로 예측 정확도를 다루는 건 아니지만, 예측 설정에 중요한 통찰을 줄 수 있다.
즉 잔차분석을 기본으로!
•표준화잔차 : 잔차/표준오차
•특잇값 : 나머지 데이터(예측값)와 멀리 떨어진 레코드(출력값)
•영향값 : 있을 때와 없을 때 회귀방정식이 큰 차이를 보이는 값(레코드)
•지렛대(레버리지) : 회귀식에 한 레코드가 미치는 영향력의 정도(유의어: 햇 값)
•비정규 잔차 : 정규분포를 따르지 않는 잔차
•이분산성 : 어떤 범위 내 출력값의 잔차가 매우 높은 분산을 보이는 경향
•편잔차그림 : 결과변수와 특정 예측변수 사이의 관계를 진단하는 그림
특잇값
= 극단값 = 대부분의 측정치에서 멀리 벗어난 값
•회귀에서의 특이값 = 실제 y 값이 예측된 값에서 멀리 떨어져 있는 경우
=> 표준화잔차(잔차/표준오차)를 조사해서 발견 가능
•표준화잔차 = 회귀선으로부터 떨어진 정도를 표준오차 개수로 표현한 값
•특잇값을 정상값들과 구분하는 데에 대한 통계 이론은 없다.
=> 어떤 관측값을 특잇값이라고 부르려면, 다수 데이터로부터 얼마나 떨어져 있어야 하는지에 대한
(임의의) 경험칙이 존재해야 한다.
Ex) X < Q1*1.5 혹은 X > Q3*1.5


•법정 담보증서의 일부 => 가격이 낮은 것 = 비정상적인 판매에 해당 => 회귀에 포함 X
•특잇값은 '부주의한' 데이터 입력 또는 단위 실수 같은 문제들 때문에 발생할 수 있다.

표준화잔차 = -4.326732
: 회귀식과 표준오차의 4배 이상 차이가 남
이에 해당하는 추정치 : 757,753달러

예측값과 가장 큰 차이를 보이는 거래 데이터에 대한 법정 담보 증서의 일부
이분산성
: 분산이 다르다, 회귀계수의 표준오차(분산)이 다르다.
왜 문제인가?
•회귀 계수의 유의성을 판단하려면 우선 t-값을 계산해야 함
•T-값은 회귀계수를 표준오차로 나눈 것
•이때 표준오차가 이분산성을 띄게 되면 하나의 수로 나타낼 수 없음
종속변수 : 주택가격
독립변수 : 거실크기
독립변수를 x축으로 종속변수를 y축으로 산포도

거실크기가 커질 수록 회귀계수의 표준오차가 커짐 -> 표준오차는 독립변수 거실크기의 함수로 표현될 수 있음

이분산성 확인 방법
•산포도
•잔차도
•White test
•Goldfeld-Quandt test
•Breusch-Pagan test
즉, 테스트 결과가 유의 하면 이분산성이 있다는 뜻
이분산성 해결 방법
1.Robust standard error(statsmodels.regression.linear_model.RegressionResults)
-구하는 방법이 복잡
-통계프로그램에 따라서 기능을 제공하기도 하고 아니기도 함
2.Weighted least square regression(WLS regression)
-이분산서의 함수를 찾아서 그 역함수로 독립변수를 만들어 추가하는 OLS
-문제는 이분산성의 함수를 찾는다는 것이 쉽지 않음
-이론적으로는 쉬우나 현식적으로는 어려움
3.GLS/FGLS regression
회귀계수의 표준오차가 동일하지 않고 변화하는 경우
회귀계수의 표준오차가 독립변수의 함수로 나타남
확인 방법
•산포도/잔차도
•White test 등
해결방법
•Robust standard error(statsmodels)
•WLS regression
•이론적으로는 쉬우나 현실적으로는 어려움
-시계열 데이터 회귀분석 자기상관 확인
•statsmodels.stats.stattools.durbin_watson
출처:
https://www.youtube.com/watch?v=SFsZVZWBfZ0
4.6.2 영향값
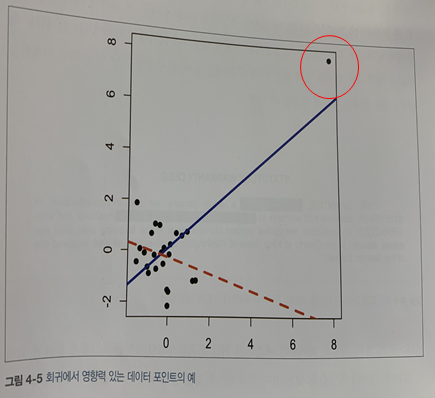
하나의 값 때문에 회귀모형에 중요한 변화를 가져오는 값을
주영향관측값 이라고 한다.
레버리지 (Leverage)
개별적인 데이터 표본이 회귀 분석 결과에 미치는 영향은 레버리지(leverage)분석을 통해 알 수 있다.
레버리지는 래의 target value y 가 예측된(predicted) target y^(yhat)에 미치는 영향을 나타낸 값이다.
self-influence, self-sensitivity 라고도 한다.
즉, 레버리지는 어떤 데이터 포인트가 예측점을 자기 자신의 위치로 끌어 당기는 정도

쿡의거리를 이용해서
쿡의거리에 해당하는 값은 원의 크기로 나타낸다(영향력있는 값)

Outlier
•Good Leverage Points
leverage가(영향력이) 높지만 residual이(오차가) 작은 데이터
•Bad Leverage Points = Outlier
leverage도(영향력도) 높지만 residual도(오차도) 큰 데이터
레버리지가 높은 데이터 중 오차가 큰 데이터, 즉 아웃라이어는 데이터의 존재 유무에 따라 회귀 분석 결과가 크게 달라진다.
4.4.2 다수의 수준을 갖는 요인변수들
편잔차그림(Partial residual plot)
•예측모델이 예측변수와 결과변수 간의 관계를 얼마나 잘 설명하는지 시각화하는 방법
•데이터 과학자들에게 가장 중요한 모델 진단 방법
편잔차
•단일 예측변수를 기반으로 한 예측값과 전체를 고려한 회귀식의 실제 잔차를 결합하여 ‘만든 결과’

python을 이용한 편잔차그림 그리기


결과물
 반응형
반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글