-
데이터과학을 위한 통계 리뷰 - 15일차 (예측변수,독립변수선택,AIC,BIC,순서가 있는 요인변수,예측변수간 상관,다중공선성)Machine Learning/데이터과학을 위한 통계 2021. 3. 15. 14:48반응형
5.5 예측변수 선택

1. 회귀계수의 영향력
다중 회귀분석의 결과로 다음의 y = 10x1 - 3x2 + 12회귀식을 얻었다고 가정합시다.
회귀식에서는 결국 독립변수가 한 단위 증가할 때 변화하는 종속변수를 확인할 수 있는데요.
당연히 회귀계수의 크기가 클수록 종속변수에 많은 영향을 줄 것입니다.
이처럼 우리는 여러 특성 중에서 어떤 특성이(독립변수) 영향력이 있는지 판단할 수 있을 겁니다.
2. Adjusted R2(수정된 결정계수)
기존에 결정계수를 하나의 평가지표로 사용할 수 있었습니다.
하지만 다중 선형 회귀분석에서는 일반적인 결정계수가 문제가 될 수 있는데, 결정계수는 SSR(회귀변동)에 따라 값이 변합니다. 하지만 독립변수의 개수가 증가함에 따라 같이 증가하여 결정계수 또한 증가하는 단점이 생깁니다.
이를 고려하기 위해 수정된 결정계수를 활용하게 됩니다. n은 데이터 샘플의 수, p는 독립변수의 개수를 의미합니다. 정리하자면 수정된 결정계수는 실제로 종속변수에 영향을 주는 변수들의 설명력을 의미한다고 볼 수 있습니다.

3. AIC(Akaike Information Criterion)
AIC는 모형의 적합도와 복잡도를 같이 고려할 수 있는 기준

SSE(제곱 오차의 최소 합)를 최소화하는 것은 R^2를 최대화하는 것
T는 추정에 사용하는 관측값의 수
P는 잔차 분산을 포함하여 추정되는 매개변수와 초기 상태의 전체 개수

AIC는 예측변수(predictor variable)를 너무 많이 고르는 경향이 있어서 편향을 수정한 AIC를 사용한다.
4. BIC(Bayesian Information Criterion)
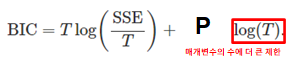
AIC 는 우도 함수에 의해 평가 된 바와 같이
적합도를 보상 하지만, 추정된 파라미터의 수의 증가하는 함수인 페널티도 포함한다.
모델의 절대 품질에 대해서는 아무 것도 말하지 않고 다른 모델에 대한 품질 만 알려줍니다.
모든 후보 모델이 적합하지 않은 경우 AIC는 이에 대해 경고하지 않습니다.
따라서 AIC를 통해 모델을 선택한 후에는 모델의 절대 품질을 검증하는 것이 좋습니다.

모델에서 모수의 수(k)를 늘리면 거의 항상 적합도를 향상시키기 때문에
이를 상쇄시키기 위하여 불필요한 파라미터에 패널티를 부여하여 모델의 품질을 평가하는 것

5.Mallows's Cp
Mallow's Cp는 최적 모형 선정 척도 중 하나입니다.
Mallow's Cp는 모든 변수를 사용한 모형과 p개의 독립변수를 사용한 모형이 얼마나 가까운가를 보여줍니다. 일반적으로 비슷한 성능이라면 더 간단한 모델이 좋기 때문에 이 통계량을 통해서 모형을 선정할 수 있습니다. 즉, 더 적은 개수의 변수로 비슷한 성능을 낼 수 있다면 이러한 간단한 모델이 좋다는 거죠.
Cp 통계량은 작을수록 좋은 값을 보입니다.
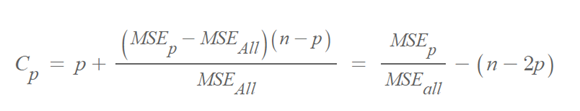
MSEp는 p개의 독립변수를 사용할 때의 MSE,
n은 관측치 수,
all은 모든 변수를 활용한 모델



전진선택법의 각 단계에서 이미 선택된 변수들의 중요도를 다시 검사 하여
중요하지 않은 변수를 제거

4.4.3 순서가 있는 요인변수
척도 : 대상의 특성을 통계상의 수로 표현하기 위해 체계적으로 그 속성에 숫자를 부여한 것




출처:
쉽게 보는 척도의 4가지 유형 - 명목척도, 서열척도, 등간척도, 비율척도
오늘은 사회·심리학 등의 분야에서 통계분석 용도로 많이 이용되는 척도의 개념과 종류에 대하여 알아보고...
blog.naver.com

출처:
https://drhongdatanote.tistory.com/8
[개념 통계 04] 통계의 시작: 척도의 종류
안녕하세요. 홍박사입니다. 이번 포스팅에서는 척도에 대해서 살펴보겠습니다. 척도(Scale)는 어떠한 대상의 특성을 단위를 사용하여 정량화한 것을 말합니다. 쉽게 말하면 척도는 대상 특성의 "
drhongdatanote.tistory.com
Chapter 4.5.1 예측변수간 상관

예측변수간 연관되어 있기
때문에 종속변수에 의해 값이 변하는게 아니라 다른 예측변수가 변하면 연관되어있는 예측변수가 변함
인과관계로 봤을 때
전혀 문제가 없는데 상관계수가 높다면, 제거를 해야한다. 안하면 교란변수가 되어서 실제로는 전혀 의미없는데 의미있는 것처럼 나올 수 있다.
다중공선성
상관관계가 매우 높은 독립변수들이 동시에 모델에 포함될 때 발생

완벽한 다중공선성 -> 같은 변수를 두 번 넣은 것 -> 최소제곱법 계산상 어려움
완벽한 다중공선성이 아니라면?
•회귀계수의 표준오차가 비정상적으로 커짐
•회귀계수의 유의성은 t-값에 의해 결정
•t-값은 회귀계수를 표준오차로 나누어서 계산됨
•표준오차가 비정상적으로 커지면 t-값이 작아져서 유의해야할 변수가 유의하지 않게 됨(p값이 커짐)
다중공선성을 어떻게 찾아 내는가?
1.산포도 & 상관계수
•상관계수가 0.9(기준X)를 넘는다면 다중공선성의 문제가 있을 수 있다.
2.허용/공차 (tolerance)를 확인
•한 개의 독립변수를 종속변수로 나머지 독립변수를 독립변수로 하는 회귀분석을 했을 때 나오는 R^2을 이용해 (1 – R^2)을 의미함
•Tolerance가 0이면 완벽한 상관성을 의미하여 다중공선성이 심각함을 의미
3.분산팽창지수(VIF : Variance Inflation Factor)
•VIF = 1 / tolerance = 1 / (1 – R^2)
•VIF가 크면 다중공선성이 크다
•연속형변수 -> 10보다 크면 문제가 있다고 판단
•더미변수 -> 3이상이면 다중공선성 의심

4.상태지수(Condition Index)
•흔하게 사용되지 않음
•100 이상이면 심각한 다중공선성이 존재
다중공선성이 발생하면 어떻게 해결해야 하나?
1.다중공선성이 큰 변수가 유의한지 아닌지 확인해야함
•다중공선성이 있음에도 해당 독립변수가 유의하다면
표준오차가 비정상적으로 팽창되었음에도 유의하다는 의미
100% 완벽한 다중공선성이 아닌 한 문제가 크게 되지 않음
•조절효과를 확인하기 위해 교호작용 변수를 추가하는 경우 연구자가 의도적으로 넣음으로써 어는 정도 다중공선성을 피할 수 없음
•연구자의 의도와 변수의 유의성에 따라 결정해야 함
2.해당 변수를 제거
•가장 일반적인 방법
•중요변수일 경우 문제가 됨
•근본적 원인은 기존연구 및 이론/논리적 구성이 사전에 부족했기 때문
3.주성분분석으로 변수를 재조합
•겹치는 분산을 제거하는 효과가 있음
•제조합된 변수들이 이상한 결과를 내는 경우가 있음
4.다중공선성이 발생한 독립변수들을 합친다.
•하나로 합쳐서 회귀분석에 사용할 수 있음
•유의하다 해도 해석이 어려워짐
•평균값을 가장 많이 사용하나 이것도 완벽하지 않음
5.능형 회귀분석
6.Mean centering 방법
 반응형
반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글