-
데이터과학을 위한 통계 리뷰 - 11일차 (복습과정,p값,Paired Sample t-test,ANOVA)Machine Learning/데이터과학을 위한 통계 2021. 3. 11. 12:46반응형
복습과정입니다.
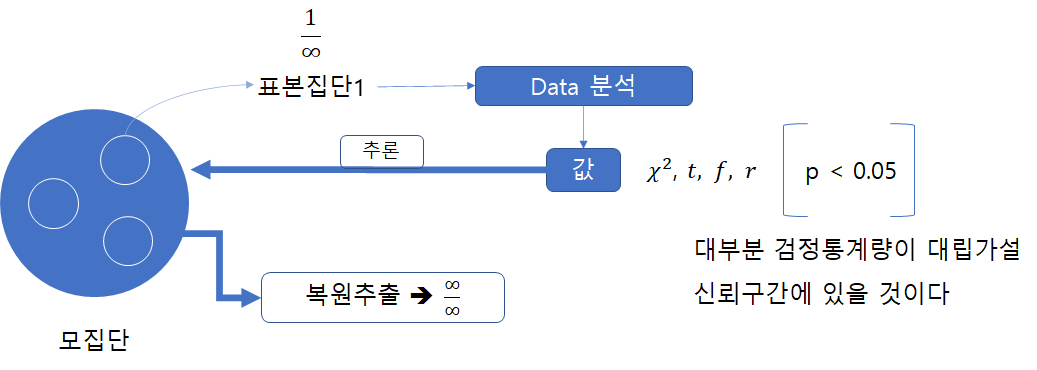
3.4 p값
통계적 유의성을 정확히 측정하기 위한 지표
(귀무가설이 맞다는 전제하에, 표본에서 실제로 관측된 통계치와 ‘같거나 더 극단적인’ 통계치가 관측될 확률)



P값(p-value) 이란?
유의 확률의 의미
P값의 오해



Paired Sample t-test


독립표본 그룹을 두개로 나눠서 평균의 차이를 보는 것,
Paired는 한사람을 두번 측정해서 뽑는것 각 사람별로 평균의 차이를 보는것




ANOVA (ANalysis Of VAriance; 분산 분석)
일원분산분석(One-way ANOVA)
종속변인은 1개이며, 독립변인의 집단도 1개인 경우.
한가지 변수의 변화가 결과 변수에 미치는 영향을 보기 위해 사용됩니다.







ANOVA 분석의 문제는 다르다는 것은 알지만,
어떤 집단간의 차이가 있는지는 알 수 없다는 것
집단간 차이가 있다?
집단이 4개 있는데 어떤 집단과 어떤 집단의 평균 차이가 있는데?
집단 4개중 평균이 모두 같진 않다. 이므로
집단간 차이를 보여주는 분석이 사후분석

•예시 Scheffe
등분산을 가정하고 사후분석
집단표본수가 같거나 다를 때 상관없이 사용 가능
다중비교를 통해 집단간의 평균차이가 있는지 모든 경우의 수를 보여줌 F통계량 사용(ANOVA)

•예시 Bonferroni
등분산을 가정하고 사후분석
집단표본수가 같거나 다를 때 상관없이 사용 가능
다중비교를 통해 집단간의 평균차이가 있는지 모든 경우의 수를 보여줌 T통계량 / T검정을 사용함
•예시 Duncan, Turkey
등분산을 가정하고 사후분석
집단표본수가 같아야 사용 가능

출처: https://partrita.github.io/posts/post-hoc-analysis
파이썬으로 사후검정(Post Hoc Analysis)
post hoc analysis
partrita.github.io
이분산일때 p < 0.05


이분산일 경우 ANOVA 의 p값(유의확률)을 보지않고
Welch 를 이용한 평균의 동질성 로버스트 검정을 사용함
사후분석은 등분산 만족하면 Scheffe,
만족하지 못하면 Games-Howell
3.9 카이제곱검정
•카이제곱 분포에 기초한 통계적 방법
•관찰된 빈도가 기대되는 빈도와 “의미있게 다른지” 여부 검증하기 위함
•자료가 범주형일 때, 특히 명목척도 자료의 분석에 이용됨


카이제곱검정 python 예시





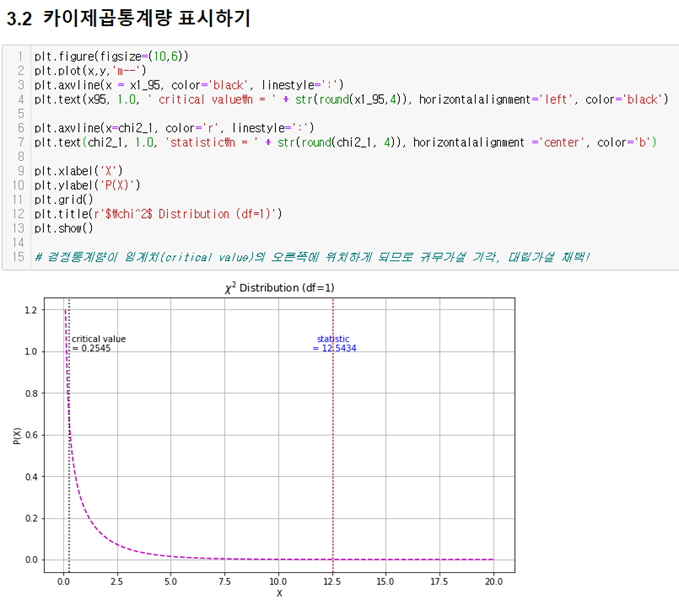
결과
대립가설 채택!
= 거주지역과 과외경험은 연관성이 있다.
( 관찰빈도 ≠ 기대빈도)
멀티암드밴딧

탐색(Exploration)과 활용(Exploitation)

Greedy 알고리즘


Epsilon-greedy 알고리즘


UCB(Upper-Confidence-Bound) 알고리즘

Tompson Sampling

★베타분포 : 두 매개변수 α, β에 따라 [0, 1] 구간에서 정의되는 연속 확률 분포들의 가족이다.
★베이즈정리 : 두 확률 변수의 사전 확률과 사후 확률 사이의 관계를 나타내는 정리다.
반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글