-
데이터과학을 위한 통계 리뷰 - 10일차 (검정통계량,Z-value,T-value,F-value,chi square,카이제곱검정,분류평가)Machine Learning/데이터과학을 위한 통계 2021. 3. 10. 14:35반응형
검정 통계량(복습)

Z-value

T-value

F-value

X^2(chi square)

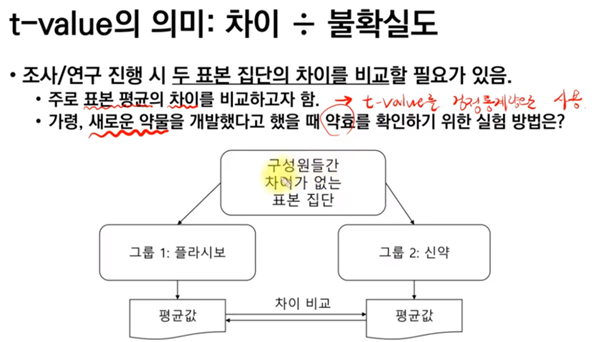
3.5. T통계량 = T-value
표본 평균 차이의 통계적 지표
F-value 와의 차이는 그룹 간 차이 정도와 불확실도를 약간 변형한다.
예) 분모 : 두 표본그룹의 평균간 차이의 불확실도 -> F- value : 표본 내에서 퍼진 정도

F-value와 T-value의 차이점


3.5 T검정
모집단의 분산이나 표준편차를 알지 못할 때,
표본으로부터 측정된 분산이나 표준편차를 이용하여 두 모집단의 평균의 차이를 알아보는 검정 방법
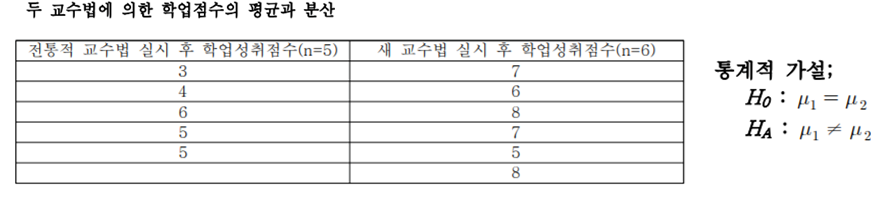
예시) 전통적 교수법과 새 교수법에 의한 학업성취도 차이를 유의수준 0.05에서 검정




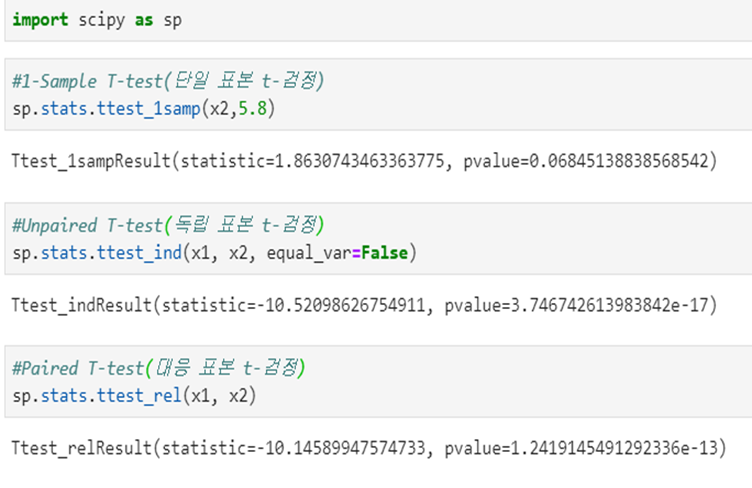
3.5 T검정-2


















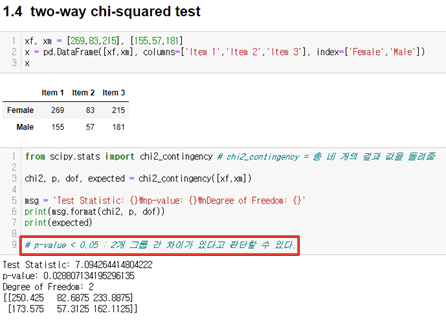
3.9 카이제곱검정
•카이제곱 분포에 기초한 통계적 방법
•관찰된 빈도가 기대되는 빈도와 “의미있게 다른지” 여부 검증하기 위함
•자료가 범주형일 때, 특히 명목척도 자료의 분석에 이용됨
구분
제품 A
제품 B
제품 C
계
관찰빈도
324
78
261
663
기대빈도
371
80
212
663




카이제곱 그래프


1. linspace() = numpy 모듈 함수. 1차원 배열 만들기, 그래프 그리기에서 수평축의 간격 만들기 등에 편리하게 사용 가능한 함수
ex) x = np.linspace(start, stop, num) : 배열 시작 값, 배열 끝 값, start와 stop 사이를 몇 개의 일정한 간격으로 요소를 만들 것인지 나타내는 것
num 생략 시 defalut 값으로 50개 수열(1차원배열) 생성함
2. pdf() : 연속확률변수의 확률밀도함수 역할을 함. 표본 값을 입력하면 해당 표본 값에 대한 확률밀도 출력
3. axvline() : 그래프 위에 세로선을 그리는 함수
4. plt.text(x 위치, y위치, ~) = 글자가 위치할 좌표 지정

분류평가
•기계학습에서 모델이나 패턴의 분류 성능 평가에 사용되는 지표.
•모델이 내놓은 답과 실제 정답의 관계로
1)정분류율(Accuracy)
Accuracy = (TP+TN)/(TN+TP+FN+FP)
2)오분류율(Error Rate)
1 - Accuracy = (FP+FN)/(TN+TP+FN+FP)
3)특이도(Specificity)
Specificity = TN/(TN+FP)(TNR :True Nagative Rate)
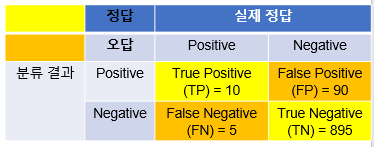
출처:
http://hleecaster.com/ml-accuracy-recall-precision-f1/
머신러닝 분류 모델의 성능 평가 지표 Accuracy, Recall, Precision, F1 - 아무튼 워라밸
분류를 수행할 수 있는 기계 학습 알고리즘을 만들고 나면, 그 분류기의 예측력을 검증/평가 해봐야 한다. 본 포스팅에서는 분류 모델의 성능을 평가할 수 있는 지표 Accuracy, Recall, Precision, F1 Score
hleecaster.com

F1 Score = 조화평균 : 두 지표를 모두 균형있게 반영하여 모델의 성능이 좋지 않다는 것을 잘 확인하기 위함이다.
출처 :
Precison, Recall, F1 score and support
머신러닝의 분야 중에 분류(classification)가 있는데요, 그 결과에 대해 성능평가(evaluation)하는 방법을...
blog.naver.com
ROC Curve(Receiver Operating Characteristic Curve)
•이진분류에 대한 성능 평가 기법.
•가로축 FPR(1 – 특이도), 세로축 TPR(민감도)
•왼쪽 상단에 가까울 수록 올바른 예측 비율이 높음
AUROC(Area Under ROC, AUC)
•ROC곡선 아래의 면적
•1에 가까울 수록 좋다.

https://nittaku.tistory.com/295
14. 다중 분류 모델의 성능측정 - Performance Measure( ACU, F1 score)
캡쳐 사진 및 글작성에 대한 도움 출저 : 유튜브 - 허민석님 머신러닝을 가지고 모델을 만들어 예측하다보면, 하나의 꼬리를 가지고 여러 classifier로 만들 수 있다. 예를 들어, kNN이나 Decision Tree
nittaku.tistory.com
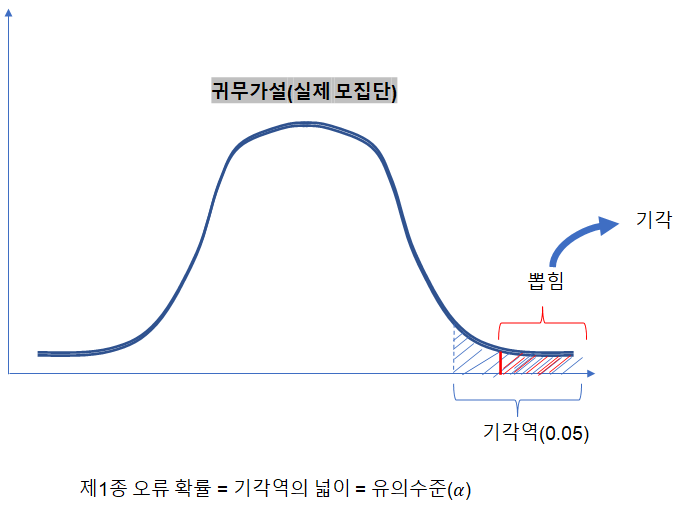
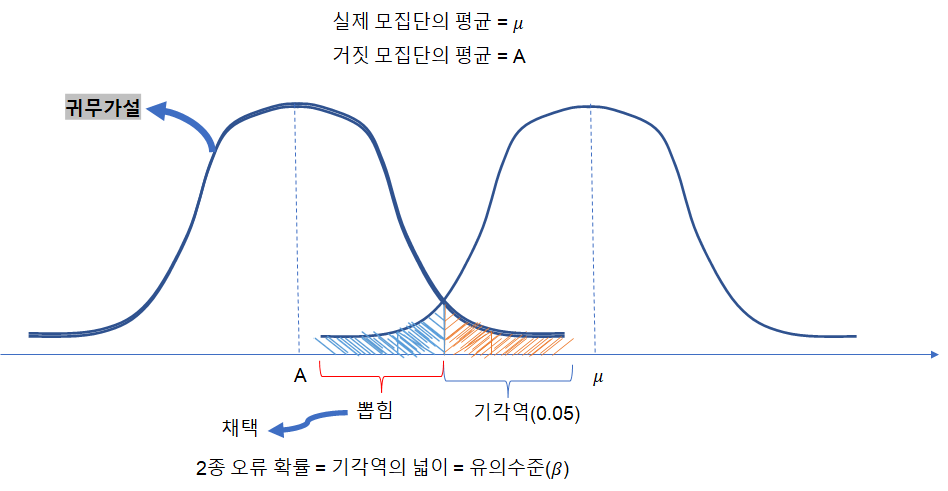
3.2 가설검정
제 1종 오류 : 귀무가설이 참인데 기각하는 것
제 2종 오류 : 귀무가설이 거짓인데 채택하는 것
α : 제1종 오류가 발생할 확률
β : 제 2종 오류가 발생할 확률
-> 가설 검정에 대한 유의 수준

출처:
https://drhongdatanote.tistory.com/59
[개념 통계 18] 귀무가설과 대립가설이란 무엇인가?
안녕하세요 홍박사입니다. 이번 포스팅에서는 통계적 가설검정에 대해서 다루어 볼 겁니다. 우선 가설을 어떻게 정의할 수 있을까요? [진실이라고 확증할 수는 없지만 "아마도 그럴 것이다." 라
drhongdatanote.tistory.com
제1종 오류
제2종 오류
귀무가설 VS 대립가설 문제 1

귀무가설 VS 대립가설 문제 2
 반응형
반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글
데이터과학을 위한 통계 리뷰 - 12일차 (복습과정,예제문제,분포) (0) 2021.03.12 데이터과학을 위한 통계 리뷰 - 11일차 (복습과정,p값,Paired Sample t-test,ANOVA) (0) 2021.03.11 데이터과학을 위한 통계 리뷰 - 9일차 (복습포함,F-value,귀무가설,대립가설,멀티암드 밴딧,greedy Algorithm) (0) 2021.03.09 데이터과학을 위한 통계 리뷰 - 8일차 (F통계량 & ANOVA, 카이제곱검정,데이터 과학과의 관련성,피셔의 정확검정) (0) 2021.03.08 데이터과학을 위한 통계 리뷰 - 7일차 (p값,t-test,다중검정,자유도,분산분석) (0) 2021.03.07