-
데이터과학을 위한 통계 리뷰 - 8일차 (F통계량 & ANOVA, 카이제곱검정,데이터 과학과의 관련성,피셔의 정확검정)Machine Learning/데이터과학을 위한 통계 2021. 3. 8. 18:44반응형
3.8.1 F통계량 & ANOVA

분산분석(Analysis of Variance, ANOVA)
1. One-way-ANOVA 일원배치분산분석
2. F통계량
3. Two-way-ANOVA 이원배치분산분석


3.8.1 F통계량
책 : 잔차 오차로 인한 분산과 그룹 평균의 분산에 대한 비율

F통계량 = F-value
차이 / 불확실도
표본 평균 차이의 통계적 지표
(즉, 본래적으로 T-value와 완전히 같은 의미)
T-value 와의 차이는 그룹 간 차이 정도와 불확실도를 약간 변형한다.
예) 분모 : 두 표본그룹의 평균간 차이의 불확실도
-> 표본 내에서 퍼진 정도
F-value는 계산한 ‘분산’ 의 비율을 척도로 이용한다.


표본 집단의 그룹 간 평균의 표준 편차란,
표본 평균의 표준편차, 즉, 표준 오차를 의미한다.

표본 집단 간 그룹 간 분산은
모집단의 모분산은 모르고 표본분산을 이용해야 하므로
δ 를 s 로 대체할 수 있다.
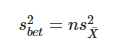

음식 외의 이유에 의한 랜덤한 몸무게의 변화는 그룹 내 분산으로 추정 할 수 있는데,
세 그룹에서 부터 얻은 분산 값을 산술평균해서 계산할 수 있다.
분산분석(Analysis of Variance, ANOVA)은
계산된 F value가 유의하게 큰지 여부를 확인해서 최소한 한 표본 집단은 다른 모집단에서 나왔는지 여부를 검증한다.

만약 이 값이 1보다 꽤 크다면(그룹 간 차이가 그룹 내의 차이보다 크다면)
즉, 모든 표본집단들이 하나의 모집단에서 나오지는 않았을 것이라는 것을 시사한다고 할 수 있다.

그룹 간 차이 = 이 차이는 음식의 영향일까? 아니면 다른 이유로 몸무게가 (랜덤하게) 변했기 때문일까?
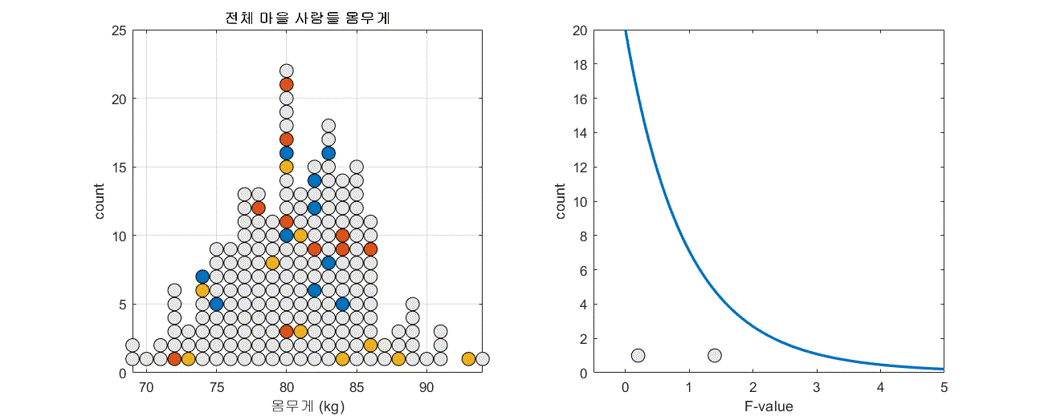

표본 그룹 간의 차이가 랜덤한 이유에 의한 것이라면 모분산 추정치의 비율은 1에 가까워야 한다.
같은 모분산을 다른 방법으로 추정한 것이기 때문이다.

주효과(하나의 변수가 미치는 영향)와
상호작용효과(두 변수가 동시에 만들어내는 영향)을 검정할 수 있음.

https://angeloyeo.github.io/2020/02/29/ANOVA.html
F-value의 의미와 분산분석 - 공돌이의 수학정리노트
angeloyeo.github.io
선형회귀에서 F통계량 :
모델 또는 모델 성분의 유의성을 검정하는 분산분석(ANOVA)방식에 대한 검정 통계량
3.9 카이제곱검정
•카이제곱 분포에 기초한 통계적 방법
•관찰된 빈도가 기대되는 빈도와 “의미있게 다른지” 여부 검증하기 위함
1.적합도 검정 : 관찰된 비율 값이 기대값과 같은지 조사하는 검정
(어떤 모집단의 표본이 그 모집단을 대표하는지 검정)
2. 동질성 검정 (변수 = 1개) : 두 집단의 분포가 동일한지 검정
3. 독립성 검정 (변수 = 2개) : 변수 사이의 연관성이 있는지 없는지 검증 => (r*c)
ex) 휴대폰 사용과 뇌암, 인종과 특정 질병
기본 가정
•변수가 범주형일 때, 자료(데이터)의 값은 개수(= 빈도, count)이어야 한다.
표본추출 시, 랜덤표본추출을 사용한다.
피어슨 잔차 : 모형이 관측치를 예측하는 정도

카이제곱 통계량 : 실제 데이터 분포와 가정된 데이터 분포 사이의 차이를 나타내는 측정값
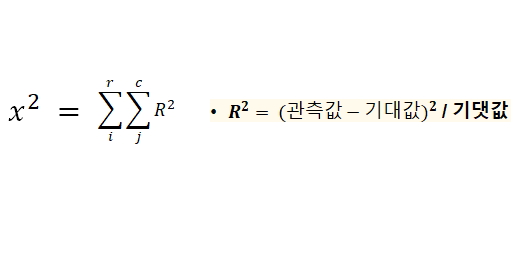
예시


출처:
[파이썬 데이터 사이언스] 카이제곱 검정(chi-squared test)
01참고자료이 포스팅은 R을 활용한 통계 분석에 대하여 파이썬을 활용하여 재작성해보는 내용을...
blog.naver.com
카이제곱검정 - 2

카이제곱검정 방법은 차이검정, 관계검정 중 관계검정에 해당하는 방법입니다.
그중에서 범주형 데이터에 대해서 검정을 하는 방법이라고 보면 됩니다.
카이제곱검정 (Chi square test)
: χ² 검정은 카이제곱 분포에 기초한 통계적 방법
: 관찰된 빈도가 기대되는 빈도와 유의하게 다른지를 검증
: 범주형 자료로 구성된 데이터 분석에 이용
: 카이제곱 값 χ² = Σ(관측값 - 기댓값)² / 기댓값
1. What is a Chi Square Test?
: 카이제곱검정에는 두 가지 형태가 있으며, 같은 카이제곱 통계량과 분포를 사용하지만 다른 목적을 가짐
ㄱ) Goodness of fit test (적합도 검정)
ㄴ) Test of -관찰된 비율 값이 기대값과 같은지 조사하는 검정 (어떤 모집단의 표본이 그 모집단을 대표는지 검정)
homogeneity (동질성 검정)
-두 집단의 분포가 동일한지 검정
ㄷ) Test for independence (독립성 검정)
-Contingency table에서 있는 두 개 이상의 변수가 서로 독립인지 검정
-기대빈도는 두 변수가 서로 상관 없고 독립적이라고 기대하는 것을 의미하며, 관찰빈도와의 차이를 통해 기대빈도의 진위여부를 밝힘
-귀무가설 : 두 변수는 연관성이 없음 (독립)
-대립가설 : 두 변수는 연관성이 있음 (독립X)

: 카이제곱 검정통계량이 카이제곱분포를 따른다면 카이제곱분포를 사용해서 가설검정 수행
: 귀무가설 하에서 검정통계량이 카이제곱분포를 따를 때,
검정통계치가
*카이제곱분포에서 일어나기 어려운 일이면 귀무가설 기각 (대립가설 채택)
*충분히 일어날 수 있는 일이면 귀무가설 기각 X
: 이 때 일어날 법한 일인지, 희귀한 경우인지의 판단 기준은 confidence level 혹은 p value
3. Chi Square P-Values
: 카이제곱검정으로 p value를 얻게 됨 (p value는 검정 결과가 얼마나 유의한가에 대한 지표)
: 카이제곱검정을 수행하고, p value를 얻기 위해 아래 두가지 정보가 필요
ㄱ) 자유도(Degrees of freedom) = n - 1 (n: 카테고리개수)
ㄴ) Alpha level(α) = 0.05 or 0.01 (연구자에 의해 결정됨)

4. The Chi-Square Distribution
: 카이제곱 분포는 감마 분포(gamma distribution)의 특수한 형태
: 카이제곱 분포는 항상 오른쪽으로 치우침
: 자유도(k)가 클수록 카이제곱 분포는 정규분포에 유사해짐
자유도(k) = (행-1) * (열-1)

3.9.3 피셔의 정확검정 (카이제곱 이후)
•카이 제곱 검정이 부정확한 경우에는 피셔의 정확 검정Fisher’s Exact Test을 사용한다.
•기대빈도가 5보다 작은 셀이 전체의 20% 이상인 경우에는 교차분석을 사용할 수 없다. 이경우 피셔의 정확검정사용
•피셔의 정확한 검정은 가능한 모든 경우의 수를 직접 따져서 가설을 검정하는 방법으로 귀무가설과 대립가설은 카이제곱 검정에서 와 같다.
•셀들의 20%를 초과하는 셀에서 기대빈도가 5미만이면 피셔의 정확검정사용
•두 변수가 관련성이 없다는 귀무가설하에서 셀에 들어갈 값이 실제 관측된 값보다 작거나 혹은 같은 경우가 나올 확률을 (p-value)구한다.
귀무가설 : 비타민 C가 감기예방에 효과가 없다.
대립가설 : 비타민 C가 감기예방에 효과가 있다.


3.9.4 데이터 과학과의 관련성
광고종류
지속 이용 사용자수
이탈 수
A
40
165
B
62
228

•A,B를 그래프를 통해 직관적으로 비교할 수 있음
•scipy 패키지를 통해 카이제곱검정 가능
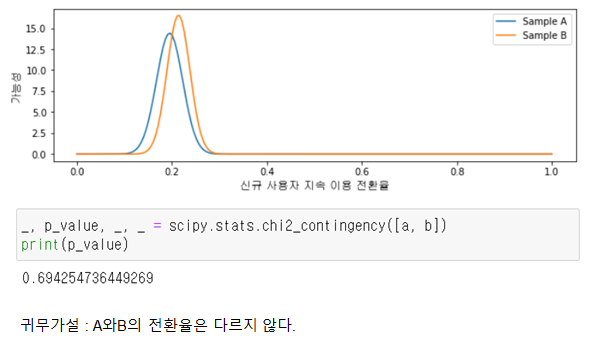
머신러닝에서 카이제곱검정을 활용한 단일변수 선택

•카이제곱검정이나 피셔의 정확검정은 최적의 처리 방법을 찾아야하는 데이터 과학에서 적합한 방법은 아님
-> 멀티암드 밴딧 방법을 사용
반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글