-
데이터과학을 위한 통계 리뷰- 5일차 (QQ plot,긴꼬리분포,t-분포,이항분포,푸아송 분포, 지수분포,고장률 추정,와이블 분포)Machine Learning/데이터과학을 위한 통계 2021. 3. 5. 16:15728x90반응형
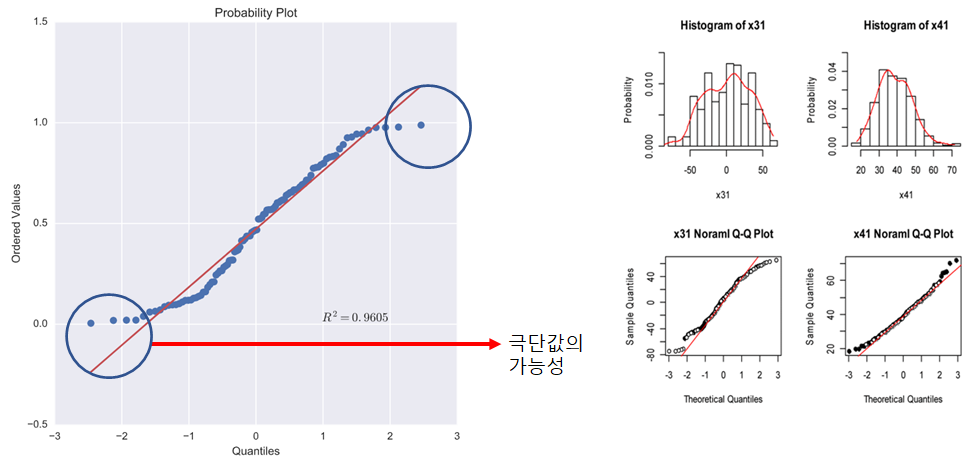
2.6.1 QQ plot (quantile-quantile Plot )
x축에는 Theoretical-Quantile 을, y축에는 획득된 샘플 값의 Empirical-Quantile (Z 점수) 을 표시
• 이론과 실제가 얼마나 차이나는지를 쉽게 표현하기 위한 Plot


Quantile 은 분위수라는 개념인데, 데이터들을 정렬한 뒤에 몇 등분으로 나눌 수 결정하고, 나눠진 등분을 구분하는 구분자를 찾는 개념
2.7 긴꼬리분포
데이터는 일반적으로 정규분포를 따르지 않는다(적은수의 극단값이 주로 존해하는 tail 을 갖음)
정규분포와 밀접한 관계 (일반적 – 왜도의 기준은 “0”)
Data의 평균의 경향 => 왜도, 표준편차의 경향 => 첨도

2.8 스튜던트의 t 분포


1. t 분포 = 연속확률분포이면서 표본분포로, 정규분포와 유사하게 생긴 t(평균)=0에서 좌우대칭을 이루는 분포
2. x축은 z점수, y축은 값
3. 분포의 모양을 결정하는 건 자유도이며, 자유도가 커질수록 표준정규분포에 가깝게 됨

t분포는 언제 사용을 할까요?
1.표본평균
2.두 표본평균 간 차이
3.회귀 파라미터
4.그 외 다른 통계량들의 분포를 구할 때
정규분포와 비슷하지만, 꼬리 부분이 약간 더 두껍고 길다.
표본의 크기가 크지 않으면 편향될 가능성이 있고, 신뢰도도 떨어진다.
그 대응책으로 예측 범위를 넓히기 위해 꼬리 부분을 조금 더 길고 두껍게 한 것.
표본이 커질수록 더 정규분포를 닮은 t 분포가 형성된다.
정리


표준화된 여러 통계 자료를 t 분포와 비교하여 신뢰구간을 추정할 수 있다.
* t 분포로 신뢰구간을 추정하고 가설검정을 할 때 t 값을 알아야 하는데, t값은 그래프의 x축 좌표
t값은 보통 't분포표'를 사용해서 구함.
a = 유의확률, n = 표본크기
1.T분포 정리 + 식
: t분포 추정 예시
: t분포 보는 법 + 개념
이항분포
용어
내용
시행(trial)
독립된 결과를 가져오는 하나의 사건(예: 동전던지기)
성공(success)
시행에 대한 관심의 결과 (유의어: 1. 즉 0에 대한 반대)
이항식(binomial)
두 가지 결과를 갖는다.(유의어: 예/아니오, 0/1, 이진
이항시행(binomial trial)
두 가지 결과를 가져오는 시행 (유의어 : 베르누이 시행)
이항분포
(binomial distribution)
X번 시행에서 성공한 횟수에 대한 분포
(유의어 : 베르누이 분포)

Ex) 우리의 목표를 학생이 수능 시험을 봤을 때 어떤 성적을 받을지 예측하는 것으로 해봅니다.
변수는 (모의) 수능 시험 성적입니다.
그리고 데이터는 실제로 변수에서 관측된 값입니다. (0점 ~ 400점)
우리는 모의 수능 시험 성적(데이터들)을 토대로 수능 시험 성적(변수)가 얼마가 나올지 예측할 수 있습니다.



2.10 푸아송 분포, 지수분포
•푸아송 분포 : 단위시간, 단위 공간에 어떤 사건이 몇 번 발생할 것인가를 표현하는 이산확률분포
극히 일어나지 않는 사건들의 일어날 확률을 구할때 사용

•Ex) 한 주에 고장 나는 횟수의 평균값이 3.4인 팝콘 기계가 있다. 기계가 3번 고장 날 확률?

#Python code import numpy as np np.random.poisson(lam=5, size=10000)
•지수분포 : 사건과 사건사이의 경과된 시간에 대한 분포, 다음 사건이 일어날 때 까지 대기시간
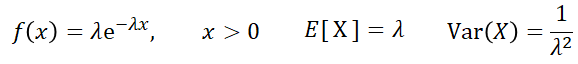
•Ex) 어느 회사에서 판매하는 전자제품의 평균수명은 3년, 보증기간은 1년이라고 한다. 그럼 이 전자제품이 1년 이내에 고장 나서, 보상받을 확률?
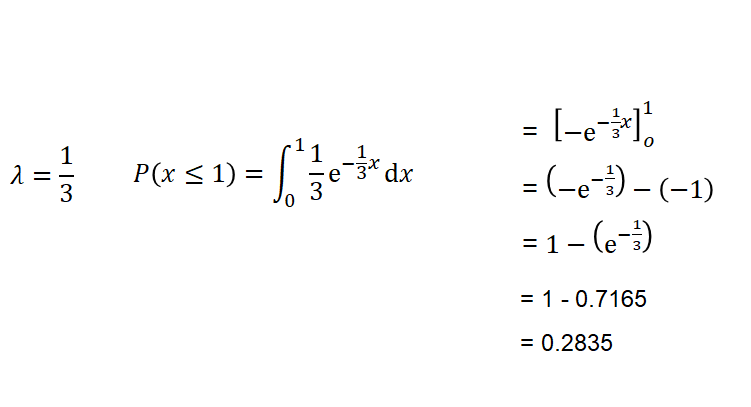
#Python code import numpy as np np.random.exponential(0.5, 10000)
2.10.3 고장률 추정
고장률(Failure rate)
: 공학 시스템이나 소자가 얼마나 자주 고장이 나는지를 측정하는 척도 (λ)
신뢰도 : R(t)
일정 시간 t 시점에서 동작하고 있는 Item의 비율
R(t) = (n(t))/N
n(t) : t 시점에서 동작하고 있는 수
N : 총 Item의 수
불신뢰도 : F(t)
일정 시간 t 시점에서 고장난 Item의 비율(누적고장확률)
F(t) = 1 - R(t) = 1 - (n(t))/N = (N - n(t))/N
R(t) + F(t) = 1
① t = 0 일 때, F(0) = 0, R(0) = 1
② t = ∞ 일 때, F(∞) = 1, R(∞) = 0
고장확률밀도함수 : f(t)
수명(고장시간)분포의 확률밀도함수
t시점과 t + ∆t 사이에서 발생한 구간 고장비율을 ∆t로 나눈 단위시간당 고장비율

고장률함수 : λ(t)
t 시점의 순간고장률

문제 예시
N = 90, 시험시간 = 6시간
동작시간
고장 수
동작 수
0~1
4
86
1~2
21
65
2~3
30
35
3~4
25
10
4~5
8
2
5~6
2
0
t=2에서 고장률은?

2.10.4 와이블 분포
와이블 분포(Weibull distribution)
: 사건 발생률(λ)가 일정한 지수분포와는 달리, 사건 발생률이 시간에 따라 변화하는 분포
 728x90반응형
728x90반응형'Machine Learning > 데이터과학을 위한 통계' 카테고리의 다른 글
데이터과학을 위한 통계 리뷰 - 7일차 (p값,t-test,다중검정,자유도,분산분석) (0) 2021.03.07 데이터과학을 위한 통계 리뷰 - 6일차 (A/B 검정,가설검정(유의성 검정),귀무가설,대립가설,재표본추출,순열검정,통계적유의성,1종오류,2종오류 (0) 2021.03.06 데이터과학을 위한 통계 리뷰 - 4일차 (표본분포,중심극한정리,Z점수,부트스트랩,신뢰구간,정규분포,재표본추출,표준오차) (0) 2021.03.04 데이터과학을 위한 통계 리뷰 - 3일차 (범주형,다변수,랜덤표본추출,편향) (0) 2021.03.03 데이터과학을 위한 통계 리뷰 - 2일차 (변이추정,백분위수,히스토그램,밀도추정,상관관계) (0) 2021.03.02