-
사이킷런(sklearn)을 이용한 머신러닝 - 4 (분류)Machine Learning 2021. 3. 13. 23:40728x90반응형
사이킷런의 traintrain_test_split이란?
- model select 전처리에 편하게 나눠서 처리할수 있게 도와주는것.
- feature
기본적인 머신러닝의 절차
-preprocessing 전처리 -> learning -> model -> predict service
- 4차 산업시대
- IOT (모든장비를 인터넷으로 묶은것)
- Bigdata
- AI
- AR(증강현실)/VR(가상현실)/MR(증강+가상)
- fintech
- BlockChain
- 가장현실적인 것
- AIOT (AI + IOT)
- 신경망 -Tensorflow -> ANN -> FFNN(feed forword) -> MLP(Multi-layer-Perceptron) XOR문제를 해결을 못해서 -> Multi layer -> 기울기소멸 -> LSTM
- preprocessing중에서 정규화를진행 해야함 ( 결측치 제거, 이상치 제거, 범주화 )
- learning (50030 데이터를 301로 가중치를 줘서 진행하면 5001 로 50030 을 대표)
- (500*30개 중에 30개의 열에서 1개의 열로 줄여야함 단. 각 열이 주는 영향을 계산을 해서 해야함.)
- 차원확대 SVM ( Support vector machine )
- 활성화 함수 (Activation function = 분류나 예측으로 결정 )
- identity 가중치에 나온값을 그대로 보내면 (회귀) (MLPRegression)
- sigmoid ( 0 ~ 1 ) -> 분류 (MLPClassifier)
- softmax 클래스가 여러개 인놈을 분류시킬때
- cost function ^(y_hat-y)
- 수학계산을 하는 solver를 결정
- learning-rate(hyper Parameter*가중치)을 가변하는것이 adam (값을 처음엔 많이 차차 줄여서.)
- 순전파 (y_hat을 만드는 과정)
- 역전파 (가중치를 조정하는 과정)
- 이걸 다합친게 tensorflow~
- 데이터를 어떻게 분류할 것인가를 놓고 이미 많은 기계학습 알고리즘이 등장했다.
- ‘의사결정나무’나 ‘베이지안망’, ‘서포트벡터머신(SVM)’, ‘인공신경망’ 등이 대표적이다.
랜덤 사이즈를 채운후 행렬제곱을 하면 -> 정방,대칭행렬
고유값분해 -> 고유치,고유벡터(정직교)
MDS 행렬곱(직교하는 2,3차원) : 2차원이나 3차원 특징추출
forward propagation 순전파 : 예측분류과정(가중치가 Random하게 초기화)
backward propagation 역전파 : 가중치 학습과정 (cost function = 기울기, learning rate)
MLP : Multi layer perceptron : FFNN(Feed forward neural network)
solver : 미분, learning-rate 조절 -> 가중치를 조절
estimator, transformer%matplotlib inline import matplotlib.pyplot as plt # 시각화 할때 import mglearn # 학습도움 # neural_network 신경망~ from sklearn.neural_network import MLPClassifier # MLPRegressor from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split X,y = make_moons(n_samples=100, noise=0.25, random_state=3) # 교육용 데이터# FONT 깨질때 폰트깨질때 from matplotlib import font_manager, rc font_name = font_manager.FontProperties(fname = "C:/Windows/Fonts/malgun.ttf").get_name() rc('font',family=font_name)# stratify 층화 변수 선택법 X_train, X_test, y_train, y_test = train_test_split(X,y, stratify=y, random_state=42) # stratify = y를 75:25 나누겠다. # Multi layer => XOR 문제를 해결하고, 레이어가 많으면 정밀도가 자동으로 높아짐 mlp = MLPClassifier(random_state=0).fit(X_train, y_train) # 가중치가 완성 ( fit ) -> layer 지정은 자동으로 MLPClassifier가 가중레이어 선정 mglearn.plots.plot_2d_separator(mlp,X_train,fill = True, alpha=.3) mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train) plt.xlabel("특성 0") plt.ylabel("특성 1")
'activation': 'relu' = 0이하를 제거한 활성화 함수(activation function)
relu는 다른 activation 함수에 비해서 빠르다.
'learning_rate': 'constant' = 변하지 않는다
'max_iter': 200 반복 횟수
epoch : 반복횟수
'solver': 'adam' = learing-rate를 조절, Momentum을 사용하는 optimizer(최적합)mlp.get_params() # 디폴트 매개변수(기본값){'activation': 'relu',
'alpha': 0.0001,
'batch_size': 'auto',
'beta_1': 0.9,
'beta_2': 0.999,
'early_stopping': False,
'epsilon': 1e-08,
'hidden_layer_sizes': (100,),
'learning_rate': 'constant',
'learning_rate_init': 0.001,
'max_iter': 200,
'momentum': 0.9,
'n_iter_no_change': 10,
'nesterovs_momentum': True,
'power_t': 0.5,
'random_state': 0,
'shuffle': True,
'solver': 'adam',
'tol': 0.0001,
'validation_fraction': 0.1,
'verbose': False,
'warm_start': False}mlp.n_layers_3
coefficient(계수) 확인
mlp.coefs_ # coefficient # bias : 계수들이 0으로 가는 것을 방지해서 처음엔 1로 셋팅[array([[ 1.96423650e-01, 1.86414048e-01, 2.73074871e-02,
1.32154297e-01, -9.48047217e-05, 2.82807555e-03,
-7.29479240e-02, 1.45878653e-01, 2.97837159e-01,
-1.12611776e-01, 2.34714552e-01, 1.30702586e-01,
-2.85623212e-02, 1.12399918e-01, -1.71442282e-01,
-3.24829063e-01, -3.85153290e-01, 2.38832765e-01,
2.13193712e-01, 2.63746115e-01, 1.70653255e-01,
7.41106685e-02, 1.04573476e-01, 6.73150355e-02,....
[-3.70726216e-01],
[ 2.00252889e-01],
[-2.78460984e-03],
[-2.01823875e-01],
[-1.45803911e-01],
[-2.40875639e-01]])]분류할 클래스 수
mlp.classes_array([0, 1], dtype=int64)
단일출력
mlp.n_outputs_1
레이어는 최소 2개, 단 10개이상주면 기울기 소실문제가 일어남
기존의 단일레이어로 사용했을 때와 다르게 멀티레이어로 XOR문제를 해결, 정확도가 높아지는 것 발견mlp = MLPClassifier(solver='lbfgs', # 과적합 random_state=0, hidden_layer_sizes=[10,5,10,2]).fit(X_train, y_train) # SVM의 논리는 : 고차원으로 데이터를 확장 (유일한놈!!) Support vector marchine # - 정확도가 높고 # - 과적합을 방지 - 그 중앙선을 찾아가기때문에!~ # SVC(Classifier) , SVR (Regressor) # 히든 레이어 사이즈 지정시 무엇을 지정하는가? # 바로 출력차수만 지정해주면 됨 (추출할 특징수) # 2*10 , 10*10 mglearn.plots.plot_2d_separator(mlp,X_train,fill = True, alpha=.3) mglearn.discrete_scatter(X_train[:,0],X_train[:,1],y_train) plt.xlabel("특성 0") plt.ylabel("특성 1")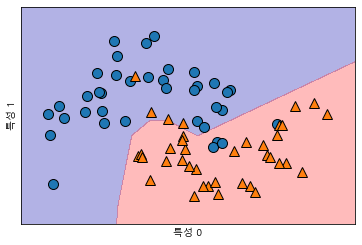
신경망은 비선형회귀/ 다차방정식에의한 비선형회귀
규제를 많이주면 산처럼 변하고 안주면 과적합됨import matplotlib.pyplot as plt # 시각화 할때 fig, axes = plt.subplots(2,4,figsize = (20,8)) for axx, n_hidden_nodes in zip(axes, [10,100]): for ax, alpha in zip(axx, [1,0.1,0.001,0.0001,0.00001]): # alpha 는 규제값임 mlp = MLPClassifier(solver='lbfgs', random_state=0, activation = 'tanh', hidden_layer_sizes=[n_hidden_nodes, n_hidden_nodes], alpha=alpha) mlp.fit(X_train,y_train) mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3,ax=ax) mglearn.discrete_scatter(X_train[:,0], X_train[:,1], y_train,ax=ax) ax.set_title("n_hidden=[{},{}]\nalpha = {:.4f}".format(n_hidden_nodes, n_hidden_nodes, alpha))
유방암 데이터를 이용한 MLPClassifier 진행
import matplotlib.pyplot as plt # 시각화 할때 # neural_network 신경망~ from sklearn.neural_network import MLPClassifier # MLPRegressor from sklearn.model_selection import train_test_split from sklearn.datasets import load_breast_cancer cancer = load_breast_cancer() print("유방암 데이터의 특성별 최대값: \n{}".format(cancer.data.max(axis=0)))유방안 데이터의 특성별 최대값:
[2.811e+01 3.928e+01 1.885e+02 2.501e+03 1.634e-01 3.454e-01 4.268e-01
2.012e-01 3.040e-01 9.744e-02 2.873e+00 4.885e+00 2.198e+01 5.422e+02
3.113e-02 1.354e-01 3.960e-01 5.279e-02 7.895e-02 2.984e-02 3.604e+01
4.954e+01 2.512e+02 4.254e+03 2.226e-01 1.058e+00 1.252e+00 2.910e-01
6.638e-01 2.075e-01]일반적으로 머신러닝을 진행했을 때
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0) mlp = MLPClassifier(random_state=42) mlp.fit(X_train,y_train) # 가중치 결정 print("훈련 세트 정확도: {:.2f}".format(mlp.score(X_train,y_train))) # 94% print("테스트 세트 정확도: {:.2f}".format(mlp.score(X_test,y_test))) mlp # 20%정도 차이나면 과적합이고 10% 정도 차이나면 고민해야함;;훈련 세트 정확도: 0.94
테스트 세트 정확도: 0.92
MLPClassifier(activation='relu', alpha=0.0001, batch_size='auto', beta_1=0.9,
beta_2=0.999, early_stopping=False, epsilon=1e-08,
hidden_layer_sizes=(100,), learning_rate='constant',
learning_rate_init=0.001, max_iter=200, momentum=0.9,
n_iter_no_change=10, nesterovs_momentum=True, power_t=0.5,
random_state=42, shuffle=True, solver='adam', tol=0.0001,
validation_fraction=0.1, verbose=False, warm_start=False)정규화를 한 후 머신러닝을 진행했을 때
mean_on_train = X_train.mean(axis=0) std_on_train = X_train.std(axis=0) # z점수 표준화~ X_train_scaled = (X_train - mean_on_train) / std_on_train X_test_scaled = (X_test - mean_on_train) / std_on_train mlp = MLPClassifier(random_state = 0) mlp.fit(X_train_scaled, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_train_scaled,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test_scaled,y_test)))훈련세트정확도: 0.991
테스트 세트 정확도: 0.965정규화를 한 후 머신러닝을 진행했을 때
mlp = MLPClassifier(max_iter=1000,random_state = 0) # max_iter=1000 천번돌려라 mlp.fit(X_train_scaled, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_train_scaled,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test_scaled,y_test)))훈련세트정확도: 1.000
테스트 세트 정확도: 0.972일반화가 잘되어있는 모델일 때
# 일반화 되었다~ 이런게 좋은 모델이다~ mlp = MLPClassifier(max_iter=1000,alpha = 1,random_state = 0) # alpha = 1 규제를줘라 mlp.fit(X_train_scaled, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_train_scaled,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test_scaled,y_test)))훈련세트정확도: 0.988
테스트 세트 정확도: 0.972입력층에 따른 가중치를 시각화한 결과
plt.figure(figsize =(20,5)) plt.imshow(mlp.coefs_[0], interpolation = 'none', cmap='viridis') plt.yticks(range(30), cancer.feature_names) plt.xlabel("은닉유닛") plt.ylabel("입력특성") plt.colorbar()
실제 데이터를 이용해서 진행하기
Data load
import pandas as pd wine = pd.read_csv('./wine_data.csv', names = ["Cultivator", "Alchol", "Malic_Acid", "Ash", "Alcalinity_of_Ash", "Magnesium", "Total_phenols", "Falvanoids", "Nonflavanoid_phenols", "Proanthocyanins", "Color_intensity", "Hue", "OD280", "Proline"], encoding="utf-8")wine.target = wine.iloc[:,:1] wine.data = wine.iloc[:,1:14]data split & normalization & fit
# Z 점수 정규화 한거~ from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(wine.data, wine.target, random_state=0) # z점수 표준화~ mean_on_train = X_train.mean(axis=0) std_on_train = X_train.std(axis=0) X_train_scaled = (X_train - mean_on_train) / std_on_train X_test_scaled = (X_test - mean_on_train) / std_on_train mlp = MLPClassifier(max_iter=60,alpha = 2,random_state=42) mlp.fit(X_train_scaled, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_train_scaled,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test_scaled,y_test)))훈련세트정확도: 0.992
테스트 세트 정확도: 0.978MinMax scale
# minmax from sklearn.preprocessing import MinMaxScaler mms = MinMaxScaler() X_mm_train_scaled = mms.fit_transform(X_train) X_mm_test_scaled = mms.fit_transform(X_test) mlp = MLPClassifier(max_iter=60,alpha = 2,random_state=42) mlp.fit(X_mm_train_scaled, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_mm_train_scaled,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_mm_test_scaled,y_test)))훈련세트정확도: 0.932
테스트 세트 정확도: 0.911not normalization
# 정규화 없이~ mlp2 = MLPClassifier(max_iter=60,alpha = 2,random_state=0) mlp2.fit(X_train, y_train) print("훈련세트정확도: {:.3f}".format(mlp.score(X_train,y_train))) print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test,y_test)))훈련세트정확도: 0.323
테스트 세트 정확도: 0.356Model 평가
# 모델평가 from sklearn.metrics import classification_report # precision = 정밀도 = TP/(TP+FP) : 예측을 중심으로 생각 # recall = 재현율 TP/(TP+TN) : 실제값을 중심으로 생각 # F1 Score = 2*(정밀도*재현율)/(정밀도+재현율) from sklearn.metrics import confusion_matrix predictions = mlp.predict(X_test) print(confusion_matrix(y_test,predictions)) print(classification_report(y_test,predictions)) # 1,2,3의 의미 unique # macro avg 평균 # weighted avg 가중평균[[16 0 0]
[ 0 21 0]
[ 0 0 8]]
precision recall f1-score support
1 1.00 1.00 1.00 16
2 1.00 1.00 1.00 21
3 1.00 1.00 1.00 8
accuracy 1.00 45
macro avg 1.00 1.00 1.00 45
weighted avg 1.00 1.00 1.00 45가중치 시각화
print(mlp.coefs_[0].shape) # 13 * 30 print(mlp.coefs_[1].shape) # 30 * 30 print(mlp.coefs_[2].shape) # 30 * 30 plt.figure(figsize=(20,5)) plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis') plt.xlabel("hidden unit") plt.ylabel("input feature") plt.colorbar()
NME(Non - negative matrix factorization) : 비음수 행렬 분해
- PCA는 음수와 양수의 차이를 상계해서 처리
- 양수인 데이터에 적용 : 음성데이터, signal
S = mglearn.datasets.make_signals() plt.figure(figsize = (6,1)) plt.plot(S, '-') plt.xlabel("시간") plt.ylabel("신호") plt.margins(0)
import numpy as np A = np.random.RandomState(0).uniform(size=(100,3)) X = np.dot(S, A.T) print("측정 데이터 형태 : {}".format(X.shape))측정 데이터 형태 : (2000, 100)
from sklearn.decomposition import NMF nmf =NMF(n_components = 3, random_state =42) S_ = nmf.fit_transform(X) print("복원한 신호 데이터 형태: {}".format(S_.shape))복원한 신호 데이터 형태: (2000, 3)
from sklearn.decomposition import PCA pca = PCA(n_components = 3) H = pca.fit_transform(X)# FONT 깨질때 폰트깨질때 from matplotlib import font_manager, rc font_name = font_manager.FontProperties(fname = "C:/Windows/Fonts/malgun.ttf").get_name() rc('font',family=font_name)# 원본,노이즈,NMF,PCA models = [S,X,S_,H] # 노이즈 : 양수 데이터는 노이즈를 제거못함 names = ['측정신호 (처음 3개)', '원본 신호', 'NMF로 복원한 신호', 'PCA로 복원한 신호'] fig,axes = plt.subplots(4,figsize=(8,4), gridspec_kw={'hspace':.5}, subplot_kw={'xticks' : (), 'yticks' : ()}) for model, name, ax in zip(models,names,axes): ax.set_title(name) ax.plot(model[:,:3],'-') ax.margins(0) 728x90반응형
728x90반응형'Machine Learning' 카테고리의 다른 글
배치 크기(batch size)를 늘리는 방법 (0) 2023.04.04 (object detection)YOLOv5 학습예제(마스크데이터셋) (4) 2021.06.23 사이킷런(sklearn)을 이용한 머신러닝 - 3 (군집,분류) (0) 2021.03.12 사이킷런(sklearn)을 이용한 머신러닝 - 2 (xgboost) (0) 2021.03.11 사이킷런(sklearn)을 이용한 머신러닝 - 1 (0) 2021.03.10