-
Spark Partitions Tuning / Part 02Data Engineering/Apache Spark 2022. 3. 4. 14:57반응형
목차
- Partitioning 이란?
- Partitioning의 종류
- Partitioning을 안할 경우
- Partitioning을 할 경우
- 주의사항
- 파티셔닝을 사용하면 도움이 되는 연산들
- coalesce와 repartition 차이점
- Partition의 종류 (Read, Write, Shuffle)
- Input Partition
- Output Partition
- Shuffle Partition
- Partitioning의 종류
- Shuffle Partition Tuning
- 최적화 실험
- 실험 구성
- 예시 코드
- 실험 1: 코어 수에 맞게 파티션 수 설정(대조군)
- 결과
- 실험 2: 파티션 수 6배 증대
- 결과
- 실험 3: 쿼리 최적화
- 결과
- 실험 4: 최적화 후 코어당 메모리 감소
- 최적화 실험 결론: 최적화 시 고려할 점
- 참고
- 각 실험별 정리
- 최종 결론
- 최적화 실험
- Reference
Partitioning 이란?
RDD의 데이터는 클러스터를 구성하는 여러 서버(노드)에 나누어 저장된다. 이때, 나누어진 데이터를 파티션이라는 단위로 관리한다.
HDFS를 사용하는 경우에는 기본적으로 HDFS 블록과 파티션이 1:1으로 구성되지만 스파크 API를 사용하면 파티션의 크기와 수를 쉽게 조정할 수있다.
이렇게 파티션의 크기와 수를 조정하고 파티션을 배치하는 방법을 설정하여 RDD의 구조를 제어하는 것을 파티셔닝 이라고 한다.
파티션의 크기나 수를 변경하느냐에 따라 애플리케이션의 성능이 크게 변할 수 있으므로 스파크의 동작을 잘 이해하고 적절하게 설정해야 한다.Partition은 RDDs나 Dataset를 구성하고 있는 최소 단위 객체입니다. 각 Partition은 서로 다른 노드에서 분산 처리됩니다.즉, 1 Core = 1 Task = 1 Partition입니다.
Spark에서는 하나의 최소 연산을 Task라고 표현하는데, 이 하나의 Task에서 하나의 Partition이 처리됩니다. 또한, 하나의 Task는 하나의 Core가 연산 처리합니다.
이처럼 설정된 Partition 수에 따라 각 Partition의 크기가 결정됩니다. 그리고 이 Partition의 크기가 결국 Core 당 필요한 메모리 크기를 결정하게 됩니다.
- Partition 수 → Core 수
- Partition 크기 → 메모리 크기
따라서, Partition의 크기와 수가 Spark 성능에 큰 영향을 미치는데, 통상적으로는 Partition의 크기가 클수록 메모리가 더 필요하고, Partition의 수가 많을수록 Core가 더 필요합니다.
- 적은 수의 Partition = 크기가 큰 Partition
- 많은 수의 Partition = 크기가 작은 Partition
즉, Partition의 수를 늘리는 것은 Task 당 필요한 메모리를 줄이고 병렬화의 정도를 늘립니다.
Spark에서 올바른 파티셔닝 방법을 선택하는 것 = 일반적인 프로그래밍에서 올바른 자료구조를 선택하는 것
Partitioning의 종류
스파크는 모든 Pair RDD에 대하여 파티셔닝이 가능하다!
키별로 노드를 지정해줄 수 는 없지만 동일한 키끼리 특정 노드에 모여있게 하는 것은 보장해준다.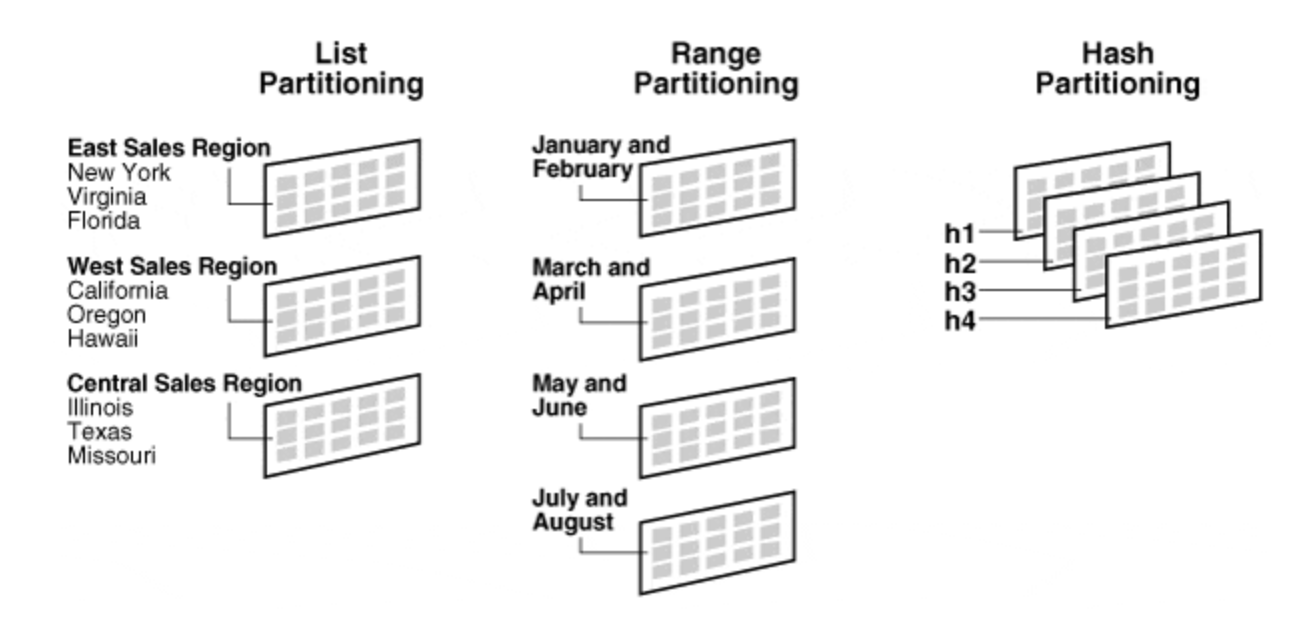
Partitioning을 안할 경우

조인을 할때마다 userData도 매번 해싱하고 셔플링이 된다. 이는 심각한 리소스 낭비이다.
Partitioning을 할 경우
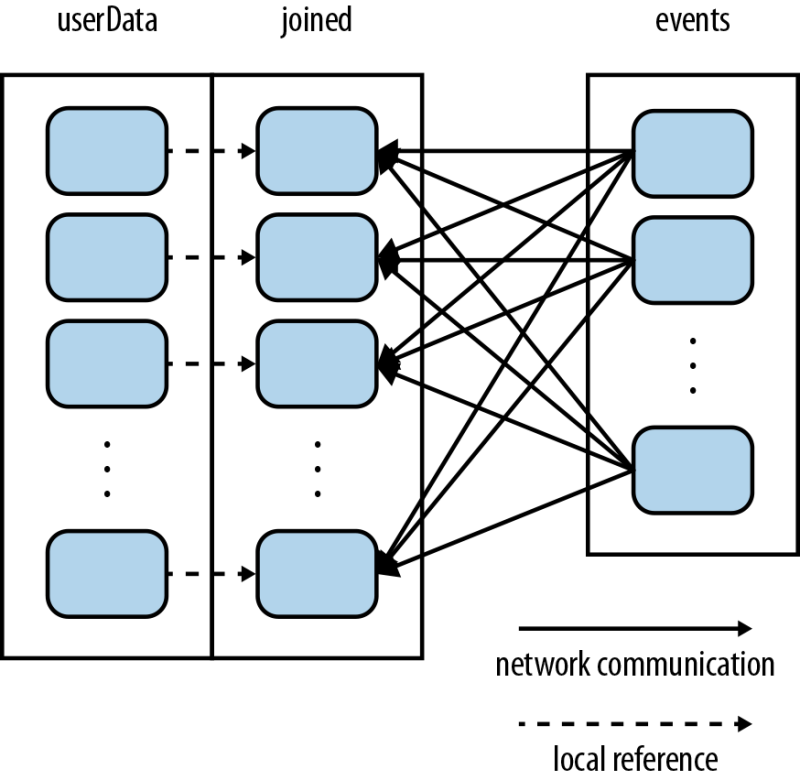
파티션을 미리 설정해두면 셔플링이 미리 이루어진다. 그렇기 때문에 조인시 아래와 같이 events만 셔플링이 일어나서 userData의 파티션이 있는 노드로 전송되어 조인이 된다! 네트워크 비용도 적게들고 속도도 빨라진다.
주의사항
partition을 사용하면 네트워크 통신 횟수와 셔플링 횟수를 줄이는 효과를 얻을 수 있다는 것을 알았습니다.
하지만 이러한 이점을 제대로 누리기 위해서는 partition을 설정한 다음에 persist()를 호출하여 영속화(캐싱)을 해줘야 합니다.
그렇지 않으면 RDD가 Lazy하게 실행될때마다 partition을 호출함에 있어서 연산도 매번 실행될 것이기 때문에 아무런 이득이 없습니다.그냥 조인하는게 더 나을지경이 됩니다.
셔플링이 단 한번만 일어나게 하는 것이 목적이라는 것을 기억하고, 꼭 persist()를 호출하여 고정시키도록 하자!(단, 데이터의 양이 크고, 한번 이하로 사용되면 persist는 하지 맙시다. 최적은 양이 적고, 많이 호출되는 데이터 셋이 적합합니다.)
파티셔닝을 사용하면 도움이 되는 연산들
사실 파티셔닝이 모든 연산에 도움이 되는 건 아니다.키별로 데이터를 셔플링하는 과정을 거치는 연산들에만 도움이 될 수 있다.
그럼 그 연산들에는 어떤 것들이 있는지 확인하면 아래와 같습니다.
`cogroup()`, `groupWith()`, `join()`, `leftOuterJoin()`, `rightOuterJoin()`, `groupByKey()`, `reduceByKey()`, `combineByKey()`, `lookup()` 등등 ..coalesce와 repartition 차이점
RDD를 생성한 뒤 filter()연산을 비롯한 다양한 트랜스포메이션 연산을 수행하다 보면 최초에 설정된 파티션 개수가 적합하지 않은 경우가 발생할 수 있다.
이 경우 coalesce()나 repartition()연산을 사용해 현재의 RDD의 파티션 개수를 조정할 수 있다.
두 메서드는 모두 파티션의 크기를 나타내는 정수를 인자로 받아서 파티션의 수를 조정한다는 점에서 공통점이 있지만 repartition()이 파티션 수를 늘리거나 줄이는 것을 모두 할 수 있는 반면 coalesce()는 줄이는 것만 가능하다.
이렇게 모든 것이 가능한 repartition()메서드가 있음에도 coalesce()메서드를 따로 두는 이유는 바로 처리 방식에 따른 성능 차이 때문이다. 즉, repartition()은 셔플을 기반으로 동작을 수행하는 데 반해 coalesce()는 강제로 셔플을 수행하라는 옵션을 지정하지 않는 한 셔플을 사용하지 않기 때문이다. 따라서 데이터 필터링 등의 작업으로 데이터 수가 줄어들어 파티션의 수를 줄이고자 할 때는 상대적으로 성능이 좋은 coalesce()를 사용하고, 파티션 수를 늘여야 하는 경우에만 repartition() 메서드를 사용하는 것이 좋다.
Partition의 종류 (Read, Write, Shuffle)
동일한 Partition이지만 쓰이는 때에 따라 분류를 합니다.
Input Partition
- spark.conf.set("spark.sql.files.maxPartitionBytes",134217728 )
Input Partition은 처음 파일을 읽을 때 생성하는 Partition입니다. 관련 설정값은 spark.sql.files.maxPartitionBytes으로, Input Partition의 크기를 설정할 수 있고, 기본값은 134217728(128MB)입니다.
파일 (HDFS 상의 마지막 경로에 존재하는 파일)의 크기가 128MB보다 크다면, Spark에서 128MB만큼 쪼개면서 파일을 읽습니다. 파일의 크기가 128MB보다 작다면 그대로 읽어 들여, 파일 하나당 Partition 하나가 됩니다.
대부분의 경우, 필요한 칼럼만 골라서 뽑아 쓰기 때문에 파일이 128MB보다 작습니다. 가끔씩 큰 파일을 다룰 경우에는 이 설정값을 조절해야 합니다.
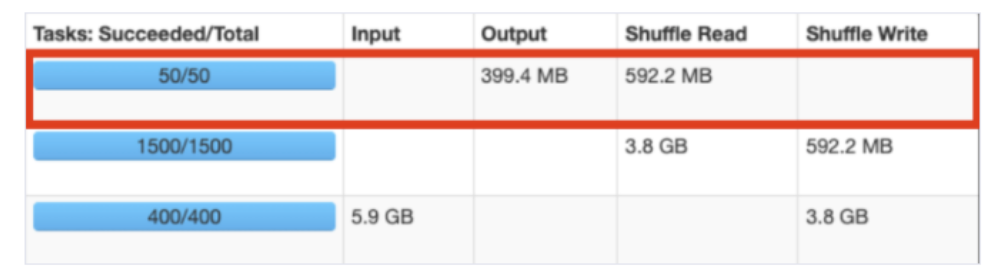
Output Partition
- coalesce()와 repartition()처럼 write시에 partition을 조정하는 옵션
Output Partition은 파일을 저장할 때 생성하는 Partition입니다. 이 Partition의 수가 HDFS 상의 마지막 경로의 파일 수를 지정합니다.
기본적으로, HDFS는 큰 파일을 다루도록 설계되어 있어, 크기가 큰 파일로 저장하는 것이 좋습니다.
보통 HDFS Blocksize에 맞게 설정하면 되는데, 카카오 Hadoop 클러스터의 HDFS Blocksize는 268435456 (256MB)로 설정되어 있어서, 통상적으로 파일 하나의 크기를 256MB에 맞도록 Partition의 수를 설정하면 됩니다.
Partition의 수는 df.repartition(cnt), df.coalesce(cnt)를 통해 설정합니다. 이 repartition와 coalesce를 이용해 Partition 수를 줄일 수 있습니다.
아래의 예시는, 파일 수를 줄여서 50개로 저장하는 모습입니다.
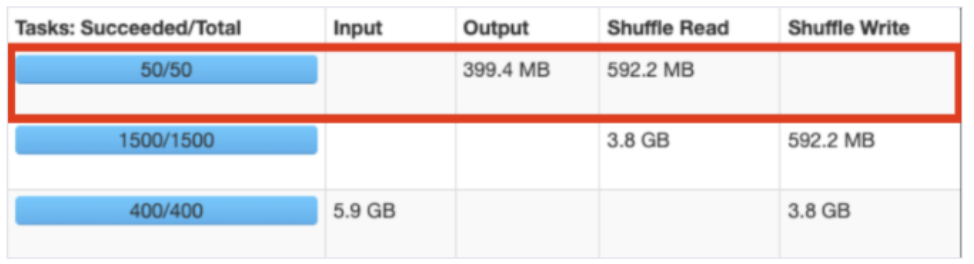
Shuffle Partition
- spark.conf.set("spark.sql.shuffle.partitions", 1800) 처럼 셔플에 사용되는 파티션 수를 설정하는 옵션
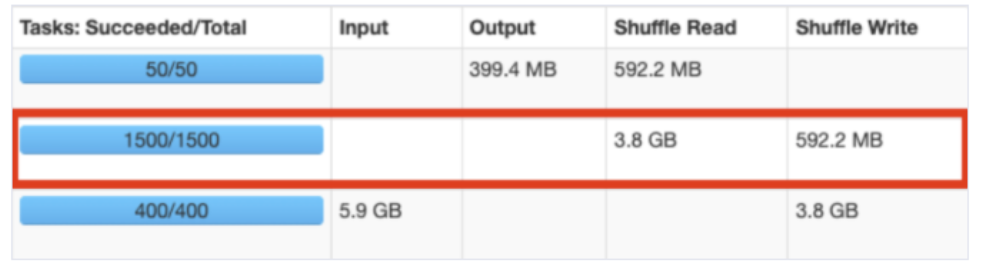
Spark 성능에 가장 크게 영향을 미치는 Partition으로, Join, groupBy 등의 연산을 수행할 때 Shuffle Partition이 쓰입니다.
설정값은 spark.sql.shuffle.partitions이고, 이 설정값에 따라 Join, groupBy 수행 시 Partition의 수(또는 Task의 수)가 결정됩니다.
이 설정값은 Core 수에 맞게 설정하라고 하지만, Partition의 크기에 맞추어서 설정해야 합니다.
이 Partition의 크기가 크고 연산에 쓰이는 메모리가 부족하다면 Shuffle Spill(데이터를 직렬화하고 스토리지에 저장, 처리 이후에는 역 직렬 화하고 연산 재개함)이 일어나기 때문입니다.
Shuffle Spill이 일어나면, Task가 지연되고 에러가 발생할 수 있습니다. 또한, Hadoop 클러스터의 사용률이 높다면, 연달아 에러가 발생하고 Spark가 강제 종료될 수 있습니다.
Memory Limit Over와 같이, Shuffle Spill도 메모리 부족으로 나타나는데, 보통 이에 대한 대응을 Core 당 메모리를 늘리는 것으로 해결합니다. 하지만, 모든 사람이 메모리가 부족하다고 메모리 할당량을 늘린다면, 클러스터가 사용성이 더 떨어지고 작업이 더욱더 실패하게 될 것입니다. 그래서 제 개인적인 생각이기도 하지만, Partition의 크기를 결정하는 옵션인 spark.sql.shuffle.partitions를 우선적으로 고려해 설정해야 한다고 생각합니다.
Shuffle Partition Tuning
최적화 실험
Shuffle Partition 크기가 100~200MB 정도 나올 수 있도록 설정하는 것이 얼마나 중요한지 다음의 최적화 실험을 통해 살펴보겠습니다.
실험 구성
실험 환경
- 카카오 Hadoop 클러스터
- spark 3.1.2
- 3 Cores X 6 GB 메모리 X 100 instances (Core 당 2GB 메모리)
다음의 데이터 집계를 예시로, Shuffle Partition에 대해 최적화를 해보겠습니다.
– data1 schema : (key, info)
– data2 schema : (key, action_name)데이터 집계에 대한 쿼리 결과는 다음과 같습니다.
쿼리 결과
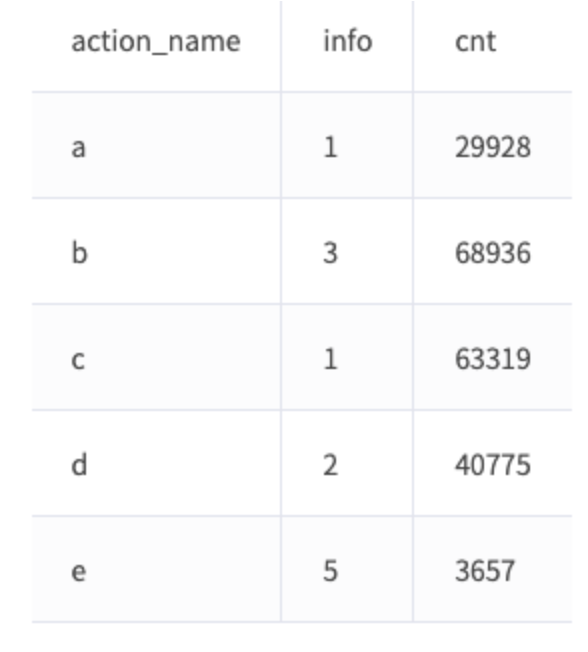
예시 코드
// // Shuffle Partition 수 설정spark.conf.set("spark.sql.shuffle.partitions", 300) val data1 = spark.sql("select * from data1") val data2 = spark.sql("select * from data2") val jExpr = data1.col("key") === data2.col("key") val joinDF = data1.join(data2, jExpr) joinDF.groupBy("action_name", "info") .agg(count(lit(1)).as("cnt")) .show실험 1: 코어 수에 맞게 파티션 수 설정(대조군)
첫 번째 실험에서는 전체 Core 수에 맞게 Partitions 수를 설정하고 위의 코드를 실행합니다.
데모 데이터와 카카오 로그를 조인해서 로그 수를 카운트하는 쿼리입니다.옵션
spark.sql.Shuffle.Partitions = 300결과

위의 코드의 실행 정보는 다음과 같습니다.
총 수행 시간은 8.4h(각 Tasks의 수행 시간의 합)이고 Task 수행 수는 306으로, 6개의 Task에서 에러가 발생해 추가적으로 연산을 수행했습니다(Locality Level Summary: Process local: 306).
Shuffle Read Size가 250GB로 Partition 당 크기가 약 850MB이고, Partition 당 Spill (memory)은 약 2.5 GB ~ 4.5 GB로, 1 Core 당 2 GB 메모리의 자원으로는 작업 수행이 힘듭니다. Hadoop 클러스터의 사용량이 높다면 에러가 반복적으로 발생하고 Spark 앱이 종료될 수 있습니다.
실험 2: 파티션 수 6배 증대
Partition 당 크기가 140MB 정도로 설정이 되도록, 대략 840MB / 6 = 140MB로, 실험 1의 Partition 수의 6배인 1800으로 Partition 수를 설정했습니다.
(또는 전체 Shuffle Size / 140MB를 하면 (250.6GB + 23.6MB) / 140MB = 약 1800)
Partition 당 크기가 140MB 정도로 설정이 되도록, 대략 840MB / 6 = 140MB로, 실험 1의 Partition 수의 6배인 1800으로 Partition 수를 설정했습니다.
(또는 전체 Shuffle Size / 140MB를 하면 (250.6GB + 23.6MB) / 140MB = 약 1800)
옵션
spark.sql.Shuffle.Partitions = 1800결과
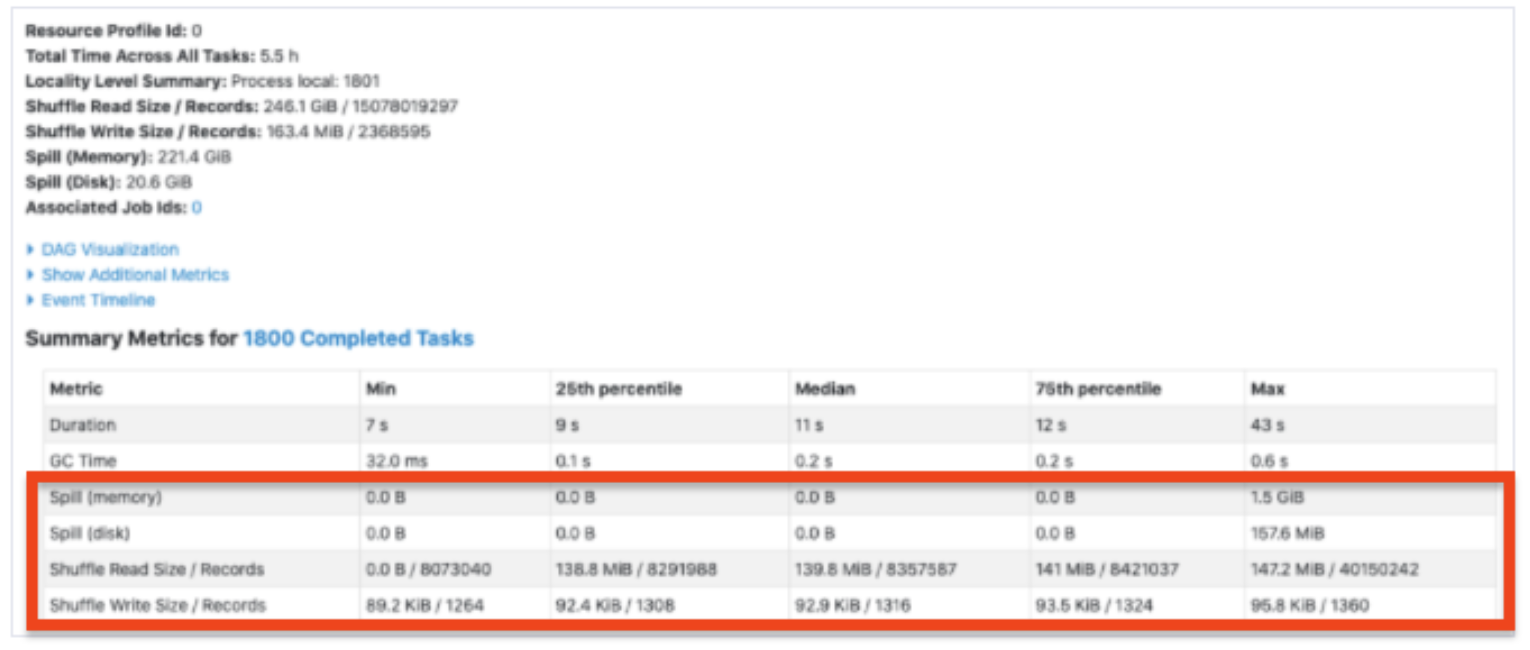
총 수행 시간은 5.5h로 Partition을 300으로 설정했을 때보다 2.9h가 줄어들었고, 총 1801개의 Task가 수행되었습니다(Task 하나에서 에러 발생).
전체 Spill은 약 221GB인데, 위의 표에서 보면 특정 Tasks(상위 25%, Max)에서 Spill이 일어났다는 것을 알 수 있습니다. 데이터가 특정 키를 기준으로 몰려있다면(skew), 이런 현상이 나타날 수 있습니다.
어떤 쿼리에서 spill이 생겼는지를 상세 확인하려면, Spark UI > SQL 탭에 들어가 보면 됩니다.
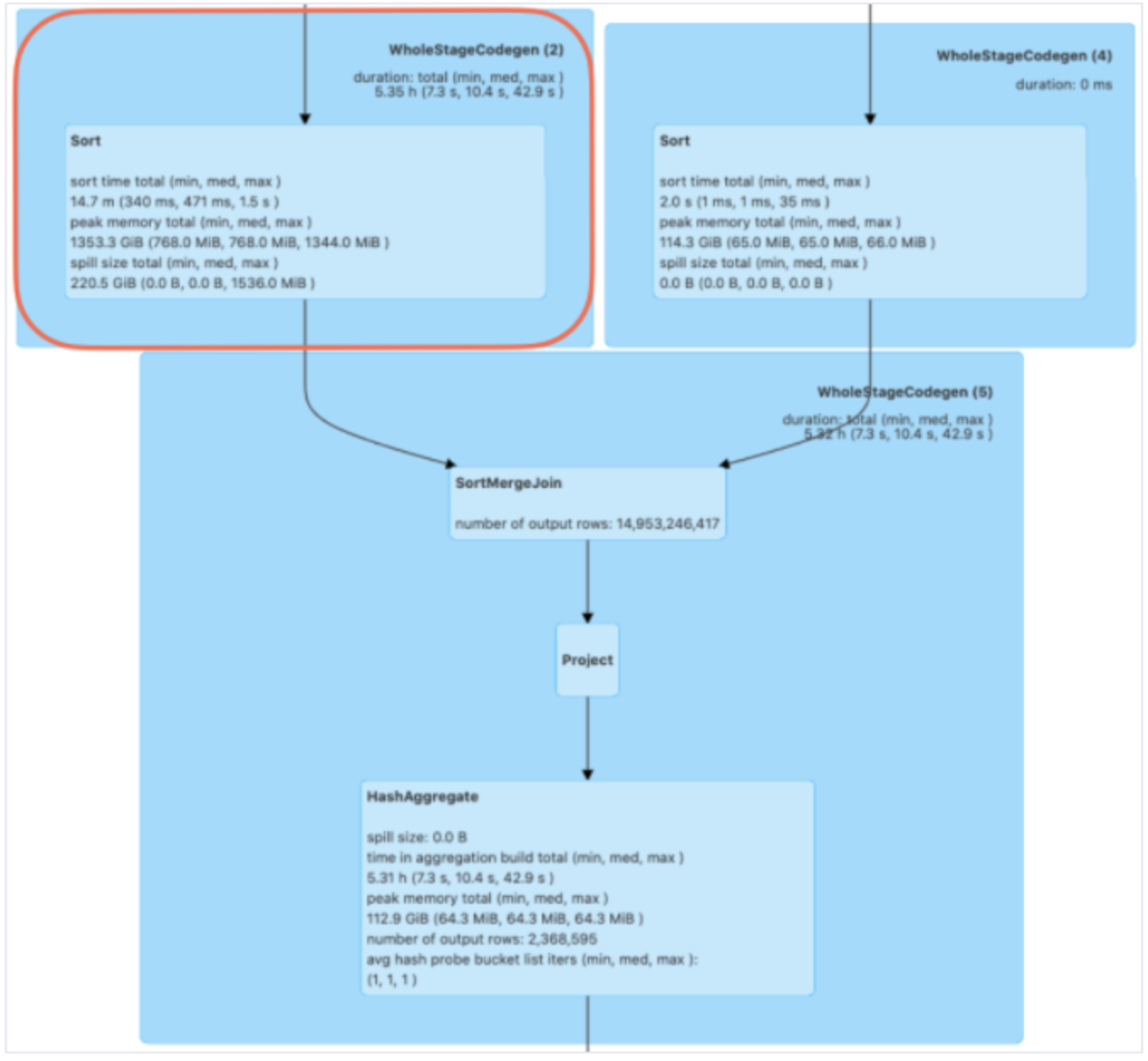
왼쪽 위 사각형에서 Join 하기 직전 Sort 부분에서 Spill이 일어난 것을 확인할 수 있습니다.
카카오 로그는 큰 편이고 특정 키를 기준으로 많은 로그 수가 존재하기 때문에, 쿼리 최적화를 해주어야 합니다.
실험 3: 쿼리 최적화
쿼리 최적화는 로그 데이터를 한번 집계를 한 뒤, 유저 데모 데이터와 Join을 하는 것으로 수정했습니다.
// Partition 수 설정spark.conf.set("spark.sql.shuffle.partitions", 1800) val data1 = spark.sql("select * from data1") val data2 = spark.sql("select * from data2") .groupBy("key", "action_name") // 조인 전 로그 수 집계 .agg(count(lit(1)).as("cnt")) val jExpr = data1.col("key") === data2.col("key") val joinDF = data1.join(data2, jExpr) joinDF.groupBy("action_name", "info") .agg(sum($"cnt").as("cnt")) .show결과
카카오 로그 집계 부분

유저 데모와 join 후 집계 부분
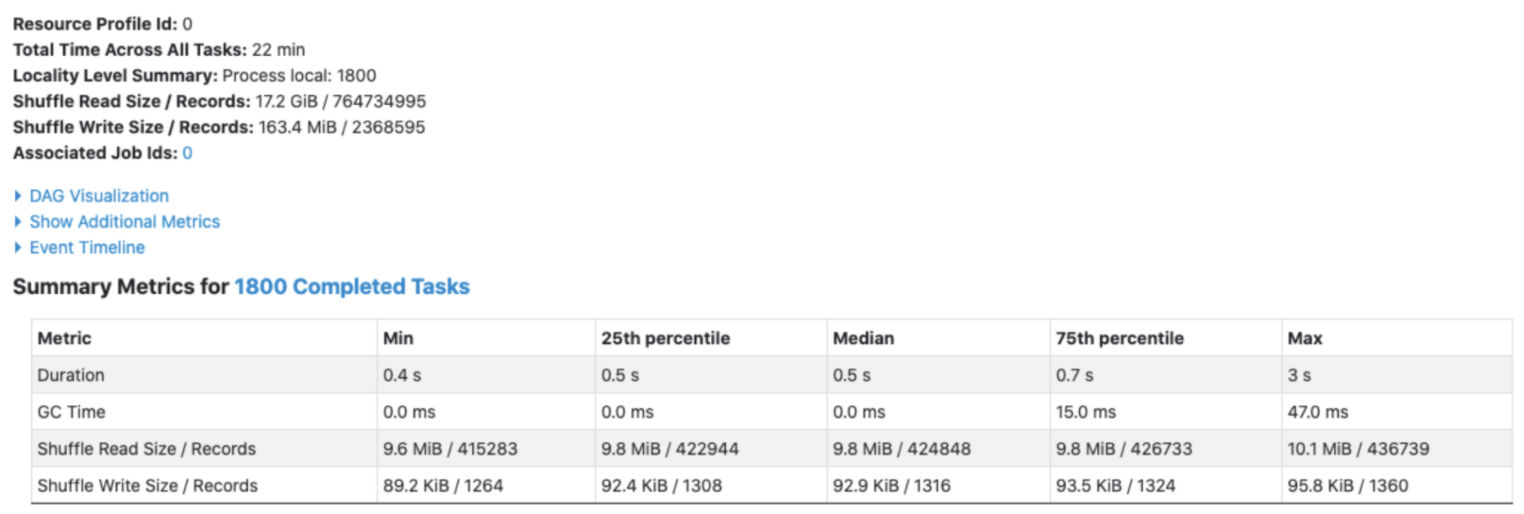
총 수행 시간은 3.3h(3.2h + 22min)으로, 쿼리 최적화를 하기 전보다 2.2h 줄어들었습니다.
카카오 로그 집계 부분과 데모와 Join 후 집계 부분 둘 다 Spill이 일어나지 않고 정상적으로 동작했습니다.
여기에서 Shuffle Read Size와 Shuffle Write Size의 총합이 300GB가 되지 않는데, 약 600GB 이상의 총 메모리를 사용하는 것이 낭비일 수 있습니다.
그래서 다음의 실험 4에서 3 Cores X 3 GB 메모리 X 100 instances로 실험을 해보았습니다.
실험 4: 최적화 후 코어당 메모리 감소
위의 쿼리 최적화를 한다면 1 Core 당 1GB 메모리에서도 정상적으로 작동합니다.

최적화 실험 결론: 최적화 시 고려할 점
위에서 Partition에 대해서 설명했지만, 가장 중요한 최적화 부분은 코드(쿼리)입니다. 최적화의 우선순위는 쿼리 > Partition 수 > Core 당 메모리 증가입니다.
쿼리는 최대한 groupBy로 집계를 한 후 Join을 하고 그다음에 Partition 수를 조절한 다음, 그래도 안된다면 Core 당 메모리를 증가시켜야 합니다.
Partition 수를 증가시킨다면 Task 수도 늘어나서 실행 시간이 증가될 수 있지만, Shuffle Spill이 일어나지 않도록 한다면 시간이 더 감소됩니다. 따라서, Shuffle Spill이 일어나지 않게 하는 선인 Shuffle Partition의 크기를 100 ~ 200MB로 설정하는 것이 최적입니다.
단, 대부분의 데이터 처리에서 위의 설정이 적합하지만, Shuffle Size가 600GB에 가깝거나 그 이상일 경우에는 Core 당 메모리를 증가시키는 것을 권장합니다. 보통 Shuffle Size가 600GB 이상이 되면 1 코어당 4GB를 고려하는 것을 권장합니다.
Cartesian join(cross join) 사용으로 Row 수가 급격하게 증가한 경우에도 Shuffle Size가 커지기 때문에 메모리 증가를 고려해야 합니다.
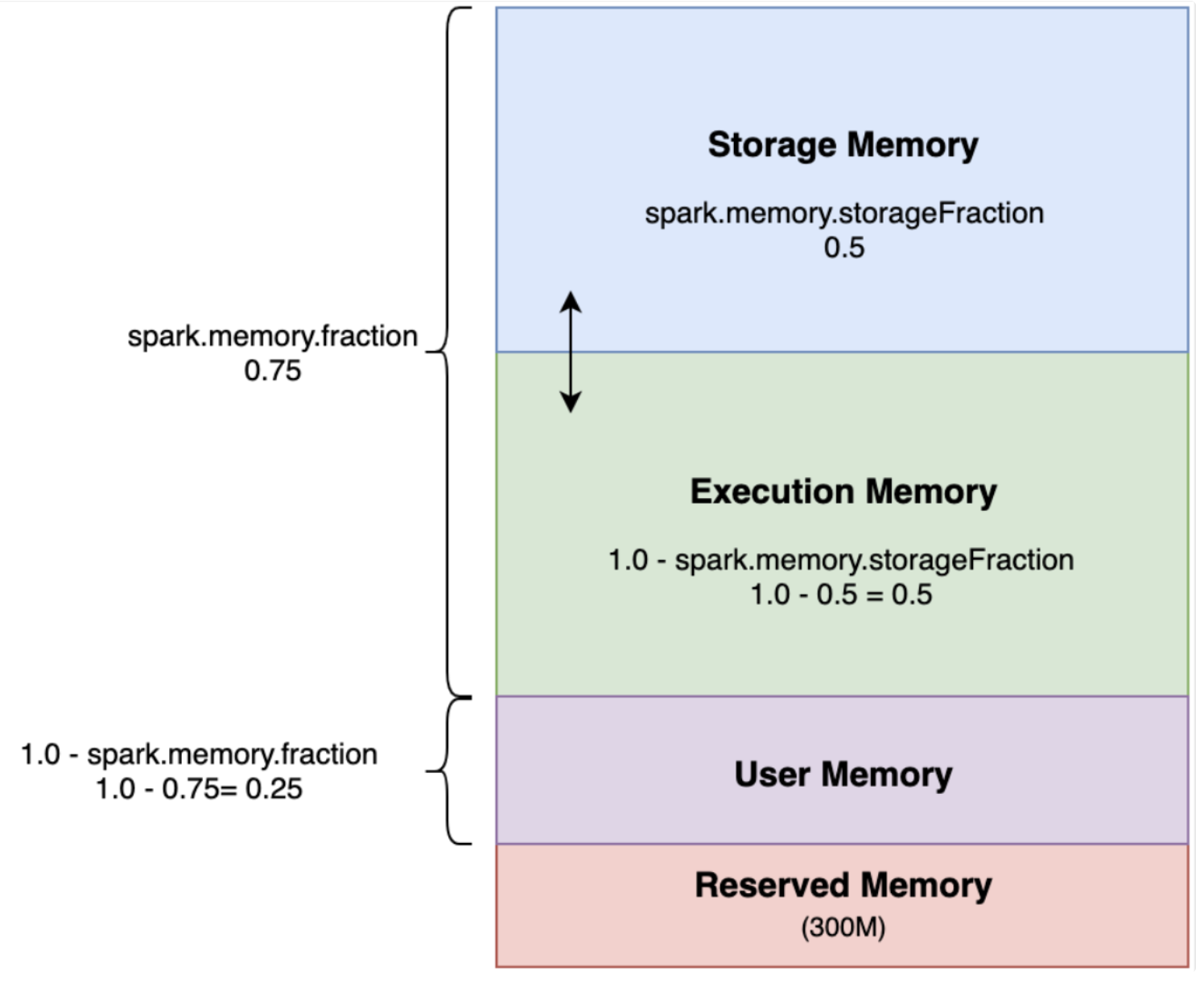
이 외에도, Spark ML을 사용하거나 Caching을 하는 경우, Spark 메모리 구조 중 Storage Memory Fraction 부분에서 캐싱을 하게 되는데, 이렇게 되면 연산(Execution)을 해야 하는 부분이 줄어들어 결국에는 메모리를 증대해야 합니다.
참고
- Storage 메모리: Spark의 Cache 데이터 저장을 위해 사용
- Execution 메모리: Shuffle, Join, Sort, Aggregation 등의 연산 과정에서 임시 데이터 저장을 위해 사용
각 실험별 정리

최종 결론
- Shuffle Spill이 일어난다면 에러가 발생해 작업이 지연될 수 있습니다. 그리고 Hadoop 클러스터가 busy 상태인 경우, 연달아 에러가 발생하고 강제 종료될 수 있습니다.
- 메모리가 부족하다면, 우선적으로 Shuffle Partition 수를 고려해야 합니다.
- Shuffle Partition의 크기를 100MB~200MB 사이로 나오도록 spark.sql.Shuffle.Partitions를 설정해야 합니다.
Reference
[Apache Spark] Partition 개수와 크기 정하기
Spark Patition의 개수와 크기는 어떻게 정하는 것이 좋을까? 판단에 기초가 될만한 기본적인 룰들과 파티션 사이즈를 기반으로 개수를 구하는 공식을 통해 알아보자.
jaemunbro.medium.com
https://brocess.tistory.com/183
[ Spark ] 스파크 coalesce와 repartition
해당 내용은 '빅데이터 분석을 위한 스파크2 프로그래밍' 책의 내용을 정리한 것입니다. 실제로 실무에서 스파크로 작업된 결과를 hdfs에 남기기전에 coalesce명령어를 써서 저장되는 파일의 개수
brocess.tistory.com
https://m.blog.naver.com/syung1104/221103154997
[Spark] Apache Spark 사용해보기 - 7. Partitioning
● Partitioning 이란? RDD의 데이터는 클러스터를 구성하는 여러 서버(노드)에 나누어 저장된다. 이때...
blog.naver.com
[Spark] Shuffle 이란?
Spark Shuffle 이란? Shuffle 은 Spark 에서 데이터를 재분배하는 방법이며, 효율적인 Spark Application 을 개발하기 위해 상당히 중요한 개념입니다. Background Shuffle 을 이해하기 위해서는, reduceByKey..
wooono.tistory.com
https://tech.kakao.com/2021/10/08/spark-shuffle-partition/
Spark Shuffle Partition과 최적화
안녕하세요. 카카오 데이터PE셀(응용분석팀)의 Logan입니다. 응용분석팀에서 식별키 성연령 개발을 담당하고 있습니다. 데이터 분석에 Spark를 메인으로 사용하고 있고, 모델링에는 Tensorflow를 주로
tech.kakao.com
반응형'Data Engineering > Apache Spark' 카테고리의 다른 글
Spark Join Tuning & Key Salting / Part 3 (0) 2022.03.05 Spark 기본기(Executor Tuning) / Part 01 (0) 2022.03.03 spark-submit 하드웨어 옵션 체크하기 (0) 2022.02.07 - Partitioning 이란?