-
Python 기초 공부 - 8 (Pandas,numpy)Programming/Python 2021. 3. 9. 18:19728x90반응형
%matplotlib inline import mglearn import matplotlib.pyplot as plt mglearn.plots.plot_scaling()정규화
표준편차를 구하는 이유 : 중심으로부터 이격이 얼마나 있는가를 확인하기 위해
분석에서는 분산이 커야 주성분 (분산이 크면 왜 이런 분포인지, 어떻게 줄일 수 있는지 연구대상이 됨)
z-score (관측치-평균)/표준편차
표준화 => 표준정규분포 (확률)
import pandas as pd import numpy as np df = pd.DataFrame([[1, np.nan, 2],[2,3,5],[np.nan,4,6]]) df
df.dropna()
df.dropna(axis='columns')
df[3] = np.nan df.dropna(axis='columns', how='all') #모두가 nan이면 없애라
data = pd.Series([1, np.nan, 2, None, 3], index=list('abcde')) dataa 1.0
b NaN
c 2.0
d NaN
e 3.0
dtype: float64data.fillna(0)a 1.0
b 0.0
c 2.0
d 0.0
e 3.0
dtype: float64data.fillna(method='ffill') #forward filla 1.0
b 1.0
c 2.0
d 2.0
e 3.0
dtype: float64data.fillna(method='bfill') #backward filla 1.0
b 2.0
c 2.0
d 3.0
e 3.0
dtype: float64import missingno as msno import matplotlib.pyplot as plt import pandas as pd df = pd.read_csv('diab.csv', header=None) msno.matrix(df) plt.show()
msno.bar(df) # na의 존재를 시각화해서 확인 plt.show()
df.dropna()
df = pd.DataFrame({'value':np.random.randint(0,100,20)}) print(df) labels = ["{0}-{1}".format(i, i+9) for i in range(0, 100, 10)] print(labels) # 0, 10, 20, ... 100 df['group'] = pd.cut(df.value, range(0, 105, 10), right=False, labels=labels) # 문자열 라벨을 이용해 범주화 # rigth = False : 오른쪽 끝은 제외value
0 31
1 57
2 73
3 67
4 51
5 97
6 21
7 50
8 51
9 71
10 96
11 10
12 71
13 15
14 18
15 65
16 97
17 65
18 32
19 74
['0-9', '10-19', '20-29', '30-39', '40-49', '50-59', '60-69', '70-79', '80-89', '90-99']범주화
# 범주화 raw_cat = pd.Categorical(['a','b','c','a'], categories=['b','c','d'], ordered=False) raw_cat[NaN, b, c, NaN]
Categories (3, object): [b, c, d]
원핫인코딩
# 원핫인코딩 : 선형회귀에서 범주형 변수는 반드시 실행 # 연속형 + 범주형 df = pd.DataFrame({'key':['b','b','a','c','a','b'], 'data1':range(6)}) pd.get_dummies(df['key'])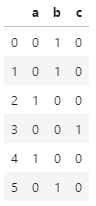
from pandas import Series, DataFrame # 메모리에서 이점이 있는 import 방식 (원하는 것만 로딩) # dict키는 중복안됨 # DataFrame = dict + 중복을 허용하고 순서를 보장 df1 = DataFrame({'key':['b','b','a','c','a','a','b'], 'data1':range(7)}) print(df1)key data1
0 b 0
1 b 1
2 a 2
3 c 3
4 a 4
5 a 5
6 b 6df2 = DataFrame({'key':['a','b','d'], 'data2':range(3)}) print(df2)key data2
0 a 0
1 b 1
2 d 2print(pd.merge(df1, df2, how='inner')) # 있는 것만!key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0print(pd.merge(df1, df2, on='key')) # 키값 일치key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0print(pd.merge(df1, df2, left_on='key', right_on='key')) # 키이름이 다를때는 이렇게 사용key data1 data2
0 b 0 1
1 b 1 1
2 b 6 1
3 a 2 0
4 a 4 0
5 a 5 0print(pd.merge(df1, df2, how='outer')) # 일치하지 않는 것도 다key data1 data2
0 b 0.0 1.0
1 b 1.0 1.0
2 b 6.0 1.0
3 a 2.0 0.0
4 a 4.0 0.0
5 a 5.0 0.0
6 c 3.0 NaN
7 d NaN 2.0# 인덱스 이름 : 계층적 인덱스를 생성 data = DataFrame(np.arange(6).reshape(2,3), index=pd.Index(['Ohio','Colorado'], name='state'), columns=pd.Index(['one','two','three'], name='number')) print(data)number one two three
state
Ohio 0 1 2
Colorado 3 4 5result = data.stack() # 데이터를 재정비해서 내가 원하는 타입으로 만들기 위해서 / r 에서는 melt print("분리") print(result)분리
state number
Ohio one 0
two 1
three 2
Colorado one 3
two 4
three 5
dtype: int32print(result.unstack())number one two three
state
Ohio 0 1 2
Colorado 3 4 5# 데이터 중복 data = pd.DataFrame({'k1':['one']*3 + ['two']*4, 'k2':[1,1,2,3,3,4,4]}) print(data) print("중복") print(data.duplicated()) print(data.drop_duplicates()) #원본을 제거하는 게 아님 data1 = data.drop_duplicates() data['v1']=range(7) print(data)k1 k2
0 one 1
1 one 1
2 one 2
3 two 3
4 two 3
5 two 4
6 two 4
중복
0 False
1 True
2 False
3 False
4 True
5 False
6 True
dtype: bool
k1 k2
0 one 1
2 one 2
3 two 3
5 two 4
k1 k2 v1
0 one 1 0
1 one 1 1
2 one 2 2
3 two 3 3
4 two 3 4
5 two 4 5
6 two 4 6data.drop_duplicates(['k1','k2'], keep='last')
data.drop_duplicates(['k1','k2']) # 포인터에 의해서 전달하기 때문에 list 형태로 전달함
data = Series([1., -999., 2., -999., -1000., 3.]) print(data)0 1.0
1 -999.0
2 2.0
3 -999.0
4 -1000.0
5 3.0
dtype: float64print("특정 데이터를 nan으로", data.replace(-999, np.nan)) print("변경", data.replace([-999, -1000], np.nan)) print("짝으로", data.replace([-999, -1000], [np.nan,0])) print(data.replace({-999:np.nan, -1000:0})) # 키 데이터 형식으로 지정특정 데이터를 nan으로 0 1.0
1 NaN
2 2.0
3 NaN
4 -1000.0
5 3.0
dtype: float64
변경 0 1.0
1 NaN
2 2.0
3 NaN
4 NaN
5 3.0
dtype: float64
짝으로 0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64
0 1.0
1 NaN
2 2.0
3 NaN
4 0.0
5 3.0
dtype: float64문제
# 문제 data = DataFrame(np.arange(12).reshape((3,4)), index=['Ohio','Colorado','New York'], columns=['one','two','three','four'])# index의 단어를 모두 대문자로 변경하시오 data.index = data.index.str.upper()data.index = data.index.map(str.upper) data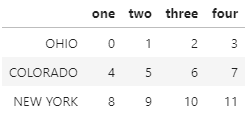
# Title : titlecase 첫자만 대문자 # https://light-tree.tistory.com/108 data.rename(index=str.title, columns=str.upper) # 특정 인덱스 수정하고 싶을 때 data.rename(index={'OHIO':'Indiana'}, columns={'three':'peekaboo'})
import pandas as pd import numpy as np from numpy import array # 다음 데이터를 18~25, 25~35, 35~60, 60~100 사이의 값으로 범주화하시오 # 나으 풀이 ages = [20,22,25,27,21,24,37,31,61,45,41,32] labels = ['18-25', '25-35', '35-60', '60-100'] range_list = [18, 25, 35, 60, 100] age_group = pd.cut(ages, range_list, right=False, labels=labels) # default는 true (right 값이 포함) age_group df = DataFrame(ages, age_group) df
# 쌤의 풀이 ages = [20,22,25,27,21,24,37,31,61,45,41,32] bins = [18, 25, 35, 60, 100] cats = pd.cut(ages, bins) cats # 범주화한 데이터 # 범주화 => 숫자로 매핑, 종류별로 숫자화 print("code", cats.codes) # 확인은 codes로 할 수 있음 print("범주의 종류는", cats.categories)code [0 0 0 1 0 0 2 1 3 2 2 1]
범주의 종류는 IntervalIndex([(18, 25], (25, 35], (35, 60], (60, 100]],
closed='right',
dtype='interval[int64]')# 범주별로 도수분포표를 작성하시오 print("범주별로 카운트 한 결과", pd.value_counts(cats))범주별로 카운트 한 결과 (18, 25] 5
(35, 60] 3
(25, 35] 3
(60, 100] 1
dtype: int64# 예제 def cut(array, bins, labels, closed='right'): _bins = pd.IntervalIndex.from_tuples(bins, closed=closed) x = pd.cut(array, _bins) x.categories = labels return x array = [3.5, 1, 0.5, 3] bins = [(0,1), (1,2), (3,4)] labels = ['first', 'second', 'third'] df = pd.DataFrame({ 'value': array, 'category': cut(array, bins, labels, closed='right') }) df다음 데이터를 로딩하고, 문제를 푸시오
path ="./olive.csv" df = pd.read_csv(path) df.head(5) # 기본 3형제, 데이터만 보면 자동으로 나와야 함 print(df.dtypes) df.describe()Unnamed: 0 object
region int64
area int64
palmitic int64
palmitoleic int64
stearic int64
oleic int64
linoleic int64
linolenic int64
arachidic int64
eicosenoic int64
dtype: object
1) 첫번째 컬럼 이름을 ID_area로 지정하시오.
df.rename(columns={df.columns[0]:'ID_area'}, inplace=True) df.columns #컬럼만 확인 df.head()
2) regions의 값들을 중복하지 않고 몇 개의 범주인지 확인하시오.
df.region.unique() df.area.unique() # crosstab : 교차분석표 pd.crosstab(df.area, df.region)
3) 처음 컬럼(ID_area)에 들어온 이상한 숫자를 제거하시오.
# 데이터 하나에 대해서 어떻게 처리할지만 정해서 apply 해주면 됨! df["ID_area"] = df["ID_area"].apply(lambda x: x.split('.')[1])
4) 산성관련성분인 'palmitic', 'palmitoleic', 'stearic', 'oleic', 'linoleic'
'linoenic', 'arachidic', 'eicosenoic'의 컬럼만 추려서 별도의 sub데이터 프레임(변수이름 dfsub)을 생성하시오.acidlist = ['palmitic', 'palmitoleic', 'stearic', 'oleic', 'linoleic', 'linolenic', 'arachidic', 'eicosenoic'] dfsub = df[acidlist] dfsub.head()
5) dfsub의 데이터를 모두 100으로 나누어 소수점으로 나타내시오.
#dfsub = dfsub/100 요래 해도 되고 ( 다 숫자데이터라 가능함 ) dfsub = df[acidlist].apply(lambda x: x/100) # apply & lambda 함수에 익숙해져야함! df[acidlist] = dfsub # 계산한 결과 반영dfsub.head()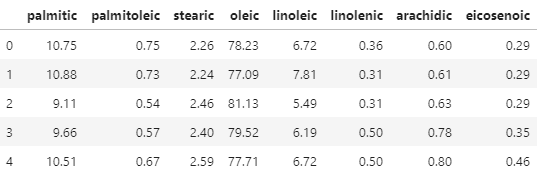
6) palmitic산과 linolenic산의 분포도를 시각화하시오.
fig = plt.figure() plt.scatter(df['palmitic'], df['linolenic']) axis = fig.gca() axis.set_title('linolenic vs palmitic') axis.set_xlabel('palmitic') axis.set_ylabel('linolenic')Text(0, 0.5, 'linolenic')

7) groupby를 활용하여 region을 기준으로 묶어서 region_groupby 객체로 생성
region_groupby =df.groupby(['region']) region_groupby.mean() # 다른방법 apply 사용(1) region_groupby.apply(np.mean) # 함수의 주소를 넘겨줌 # 참고 : 여러 함수 적용 시 aggFunc
또 다른 방법 apply 사용(2)
region_groupby.apply(lambda x : x.mean()) # x가 시리즈 ()를 붙여서 실행시킴
8) region_groupby에 describe() 메소드 적용하여 출력해보시오.
region_groupby.describe() 728x90반응형
728x90반응형'Programming > Python' 카테고리의 다른 글
명사 사전 만들기(우리말샘) (4) 2021.03.12 Python 기초 공부 - 7 (numpy) (0) 2021.03.09 Python 기초 공부 - 6 (Pandas) (0) 2021.03.08 Python 기초 공부 - 5 (mariaDB 연동) (0) 2021.03.07 Python 기초 공부 - 4 (0) 2021.03.06