데이터과학을 위한 통계 리뷰 - 4일차 (표본분포,중심극한정리,Z점수,부트스트랩,신뢰구간,정규분포,재표본추출,표준오차)
2.2.1 평균으로의 회귀
주어진 어떤 변수를 연속적으로 측정했을 때 나타나는 현상
(평균 회귀, 회귀 효과)

극단적이거나 이례적인 결과는 많은 자료를 토대로 할 때 결국 평균에 가깝게 되돌아오는 경향을 보인다.
키가 큰 부모가 키가 큰 자녀를 낳는 것은 분명하지만 평균보다 키가 큰 아버지의 아들은 아버지보다 키가 작은 경향 (기울기가 더 작음)
평균보다 키가 작은 아버지의 아들은 아버지보다 키가 큰 경향 (평균을 중심으로 달라짐)
특정 행동을 여러 차례 반복하면 극단적인 결과가 나오더라도 결국 중심으로 회귀한다.
2.3 통계학에서의 표본분포
표본분포 : 하나의 동일한 모집단에서 얻은 여러 샘플에 대한 표본통계량의 분포

표본분포 : 하나의 동일한 모집단에서 얻은 여러 샘플에 대한 표본통계량의 분포

표본평균의 분포는 모집단평균 분포에 비해 좁고 종 모양을 보이며, 정규분포를 따르게 된다.

python에서 표본 추출
np.random.permutation() Series.sample() / DataFrame.sample(n=추출샘플수, replace=False)



N=5 5개의 row를 random하게 return 해준다.
n 대신 frac을 입력하면 전체 row에서 몇%의 데이터를 return할 것인지 정할 수 있다.
단, frac을 이용하면 전체 데이터의 shuffling도 해볼 수 있다.
2.3.1 중심극한정리
모집단이 [ 평균이 μ이고 표준편차가 ∂인 임의의 분포 ]를 이룬다고 할 때 이 모집단으로부터 추출된 표본의 크기 N이 충분히 크다면,
표본 평균들이 이루는 분포는 [평균이 μ이고 표준편차가 ∂ / √n 인 정규분포] 에 근접한다.

표본의 크기가 커질수록 표본 평균들이 이루는 분포가 모집단의 평균 μ, 표준편차가 ∂ / √n 인 정규분포에 가까워진다는 정리
* 일반적으로 N >= 30
중요한 이유는 표본 수집을 기반으로 한 추리통계에서 아주 중요한 이론적 근거를 제시하고 있기 때문입니다.
모집단이 [ 평균이 u이고 표준편차가 시그마인 임의의 분포 ]를 이룬다고 할 때, 이 모집단으로부터 추출된 표본의
"표본의 크기 n이 충분히 크다"면 표본 평균들이 이루는 분포는 [ 평균이 u이고 표준편차가 a/루트 n인 정규분포 ] 에 근접한다.
중심극한정리에서의 표본평균분포란, "모집단에서 표본크기가 n인 표본을 여러 번 추출했을 때, 각각의 표본 평균들이 이루는 분포"이다.
ex) 모집단(n= 30)에서 여러번 추출(200번), 각각의 표본(x1(n=30),x2(n=30),x3(n=30) ...)
* 표본의 크기가 커질수록 (보통 30 이상), 표본 평균들이 이루는 분포가 모집단의 평균 u, 그리고 표준편차가 시그마/루트 n인 정규분포에 가까워진다는 정리


그렇다면 왜 중요할까?
: 표본 수집을 기반으로 한 추리통계에서 아주 중요한 이론적 근거를 제시하고 있기 때문.
표본의 크기가 충분히 크다면 표본평균들의 분포가 모집단의 모수를 기반으로 한 정규분포를 이룬다는 점을 이용하여, 특정 사건이 일어날 확률값을 계산할 수 있게 된다.
Þ표본 평균들이 이루는 표본 분포와 모집단 간의 관계를 증명함으로써, 수집한 표본의 통계량을 이용해 모집단의 모수를 추정할 수 있는 수학적(확률적) 근거를 마련해 줌
https://drhongdatanote.tistory.com/57
2.3.2 표준오차 : 표본 분포의 표준 편차
통계에 대한 표본분포의 변동성을 한 마디로 말해주는 단일 측정 지표
표본 값들의 표준편차 s와 표본크기 n을 기반으로 한 통계량을 이용하여 추정 가능
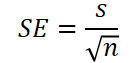
표본크기(N)가 커지면 표준오차가 줄어든다. 이 관계는 ‘n제곱근의 법칙’이라고 한다.

표준오차 측정 시 고려사항

* 표준오차 = 표본 간의 변동성을 측정함.
* 평균의 표준 오차를 사용하여 표본의 평균이 모평균을 얼마나 정확하게 추정하는지 확인할 수 있습니다.
* 일반적으로, 표준편차가 클수록 평균의 표준 오차가 더 크고 추정치가 덜 정확합니다. 표본크기가 클수록 평균의 표준 오차가 더 작고 추정치가 더 정확하게 됩니다.
•표준오차가 줄어든다. = 추정치가 더 정확하게 계산된다.
•출처 : https://goodtogreate.tistory.com/entry/%ED%91%9C%EC%A4%80%EC%98%A4%EC%B0%A8-Standard-Error
•표준편차 : (변량-평균)의 제곱의 평균에 루트를 씌운 값 : 개별 데이터 포인트의 변동성 측정
•표준오차 : (추정값-참값)의 제곱의 평균에 루트를 씌운 값 : 표본 측정 지표의 변동성 측정
* 주의할점


새 샘플을 수집하는 접근 방식은 일반적으로 불가능하고, 통계적으로도 낭비가 심하다.
이런 접근 방식을 사용하지 않아도 된다는 것이 밝혀졌고, 이는 부트스트랩 재표본으로 사용할 수 있다.
2.4 부트스트랩
부트스트랩 표본 : 관측 데이터의 집합으로 부터 얻은 샘플을 복원추출하여 표본으로 사용

변수는 (모의) 수능 시험 성적입니다.
그리고 데이터는 실제로 변수에서 관측된 값이지요. (0점 ~ 400점)
우리는 모의 수능 시험 성적(데이터들)을 토대로 수능 시험 성적(변수)가 얼마가 나올지 예측할 수 있습니다.
재표본추출 대 스트래핑
재표집(재표본추출, 리샘플링) : 관측 데이터로부터 반복해서 표본추출하는 과정, 부트스트랩과 순열 과정을 포함한다.

신뢰구간
•신뢰구간 : 모수가 실제로 포함될 것으로 예측되는 범위
•신뢰수준 : 신뢰구간에 포함될 확률
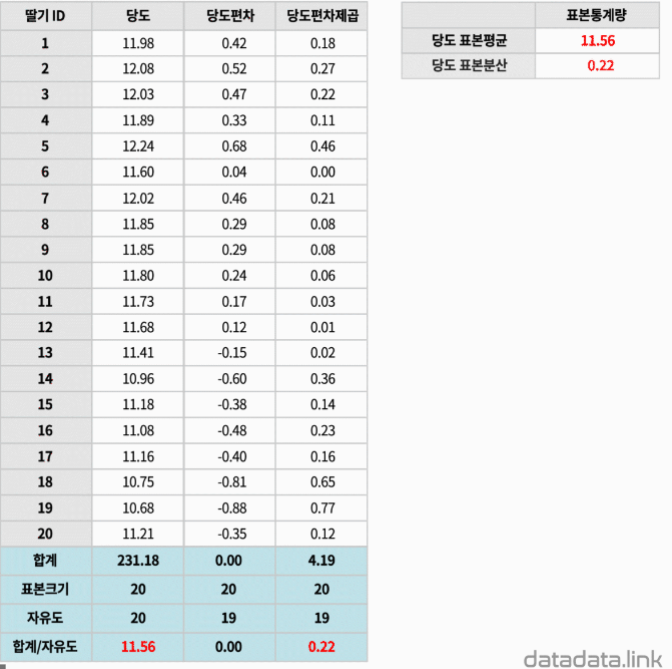
Z점수 : 평균값에서 표준편차의 몇배
정도 떨어져 있다는 것을 평가하는 수치
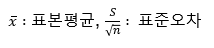
•표준오차 사용 이유 : 표준오차는 추정치의 정확도를 알려주는 값. 표준오차가 작을 수록 추정치가 더욱 정밀하다는 것을 의미한다.
신뢰구간이란 모수가 실제로 포함될 것으로 예측되는 범위라고 하는데 간단하게 어디부터 어디까지 신뢰구간이라고 할 수 있고, 신뢰수준은 모수가 신뢰구간에 포함될 활률이 신뢰 수준이라고 한다.
신뢰구간을 구하는 이유 : 모집단의 평균을 추정하는데 표본평균이 어느 정도로 신뢰할 수 있는지 알아보기 위해
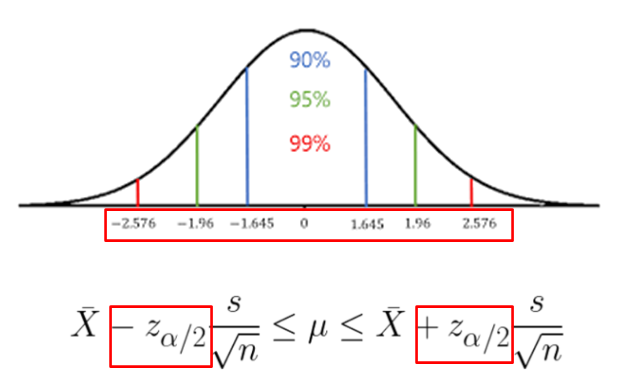
신뢰구간을 구하는 공식은 표본평균 플러스 마이너스 z점수 곱하기 표본오차입니다.
신뢰수준이 높을 수록 구간이 더 넓어진다.
표본이 클 수록 구간이 좁아진다(확실성이 커진다.)
2.6 정규분포
정규분포(Normal distribution) : 좌우대칭의 종 모양으로 생긴 분포
정규분포의 특징
-평균 = 최빈값 = 중앙값
-평균(μ)를 기준으로 좌우 대칭
-평균과 표준편차(σ)의 크기에 따라 모양이 달라짐(가우스 분포)

평균과 표준편차가 서로 다른 정규분포 비교
-> 두 정규 분포를 표준화

표준 정규분포(Standard normal distribution)
-정규분포의 평균(μ )을 0, 표준편차(σ )를 1로 만든 분포
-x축의 단위가 평균의 표준편차
표준 정규분포로 변환하는 척도 : Z-점수(Z-score)
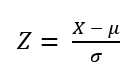
-분자 : 개별 데이터가 평균으로부터 얼마나 떨어져 있는가?
-분모 : 떨어진 정도가 표준편차의 몇 배 정도 인가?

Z-점수
-정규 분포의 확률밀도함수를 통해
-Z 점수에 따라 전체 데이터 속에서 위치와 확률을 알 수 있음


2.6.1 표준정규분포와 QQ그림
Q-Q 그림(Quantile-Quantile plot)
-데이터가 정규 분포인지 아닌지 시각적으로 간단하게 확인하는 방법
-X축은 정규분포의 해당 분위수, y축은 z점수
-y = x 그래프 위에 위치할 수록 정규분포를 보임
-파이썬에서 scipy의 probplot을 이용하여 작성
