Llama3 출시 및 사용법, fine-tuning code
https://ai.meta.com/blog/meta-llama-3/
Introducing Meta Llama 3: The most capable openly available LLM to date
In the development of Llama 3, we looked at model performance on standard benchmarks and also sought to optimize for performance for real-world scenarios. To this end, we developed a new high-quality human evaluation set. This evaluation set contains 1,800
ai.meta.com

2024년 04월 19일 새벽에 출시된 Llama3 입니다.
성능은 gemma, mistral 7b 보다 좋다고 하니깐 사실상 현존하는 sLLM 중에서는 가장 성능이 좋을 듯 하네요.
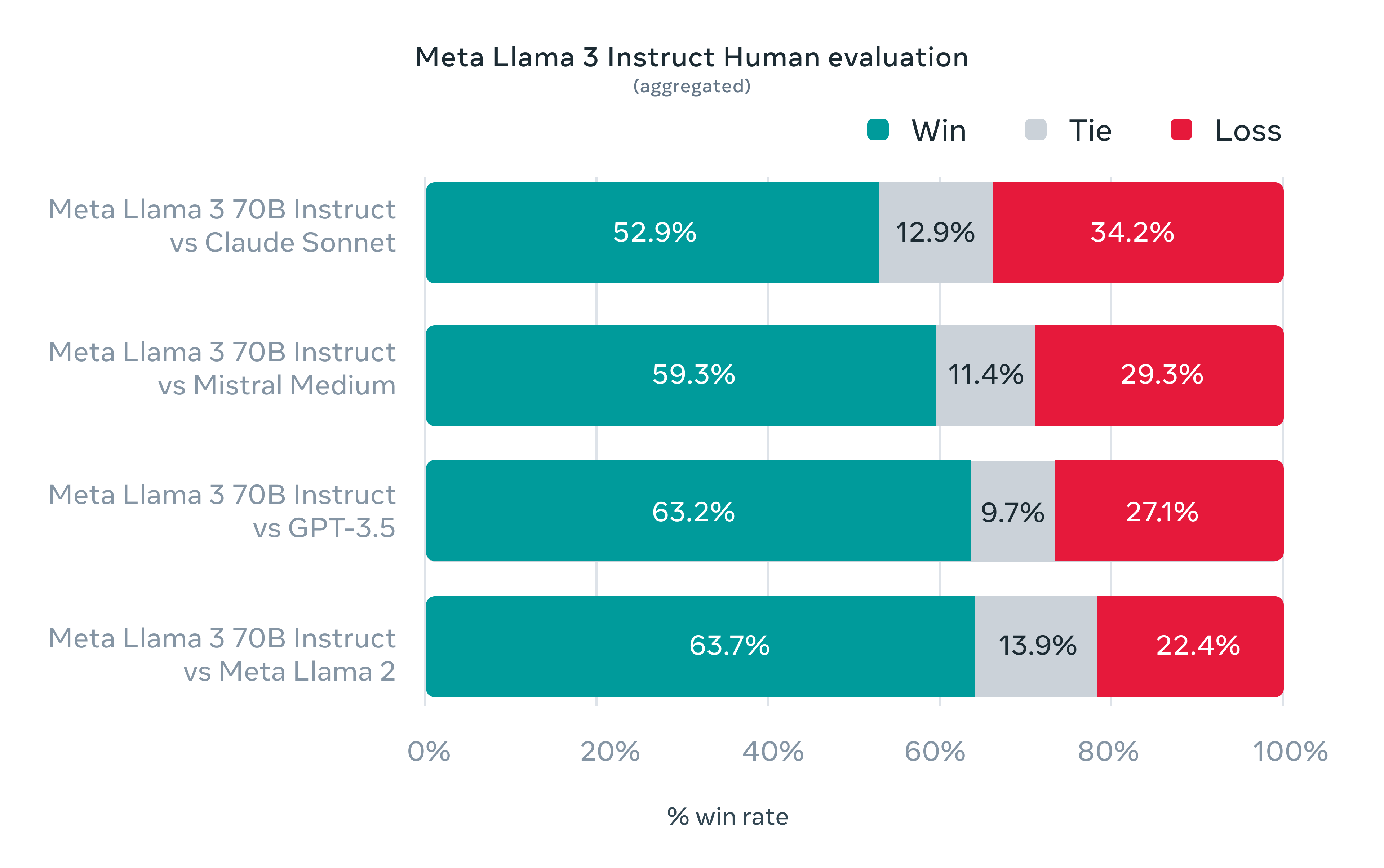
70B 기준으로도 클로드3의 sonnet, mistral medium과 gpt-3.5까지 이기는 모습을 보이네요.
짧게 요약하자면 최대 토큰 8,192 tokens
vocab size 128k, GQA(group query attention) 사용
굉장히 질 좋은 데이터셋으로 Pre-trained 진행 총 학습 토큰은 15T tokens(15조 토큰 갯수)
24k(24,000)개의 GPU Cluster 구성 학습
다국어 데이터(30국어) 학습
instruct model의 학습 방법은 SFT -> PPO -> DPO 사용
그리고 400B 짜리 모델도 학습 중인 것으로... 성능은 굉장히 높음

대략적인 모델들의 성능은 다음 페이지 참고:
https://paperswithcode.com/sota/multi-task-language-understanding-on-mmlu
Papers with Code - MMLU Benchmark (Multi-task Language Understanding)
The current state-of-the-art on MMLU is Gemini Ultra ~1760B. See a full comparison of 107 papers with code.
paperswithcode.com
fine-tuning code는 일반적인 16gb GPU 기준으로 unsloth 패키지를 사용해서, 학습하면 될 듯 합니다.
unsloth는 04/19 기준으로 아직 DDP 지원이 안됨(multi gpu) 1개 GPU만 가능
https://github.com/unslothai/unsloth.git
GitHub - unslothai/unsloth: 2-5X faster 80% less memory LLM finetuning
2-5X faster 80% less memory LLM finetuning. Contribute to unslothai/unsloth development by creating an account on GitHub.
github.com
https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp?usp=sharing
Alpaca + Llama-3 8b full example.ipynb
Colab notebook
colab.research.google.com
끝.